How to use a proxy with Scrapy
This guide shows you how to integrate HypeProxies with Scrapy to handle IP restrictions, geographical limitations, and rate limiting in your web scraping applications.

$1 one-time verification. Unlock your trial today.

Speed
Success
Consistency
Reliability
Flexibility
What is Scrapy
Scrapy is a powerful open-source Python framework for web scraping and crawling. It enables you to write spiders that extract data from websites efficiently. However, when scraping at scale, you often encounter IP bans, geo-restrictions, and rate limits that can halt your data collection efforts.
Proxies solve these challenges by masking your IP address and enabling you to rotate between different network endpoints, helping you avoid detection and maintain consistent access to your target websites.
Prerequisites and setup
Before adding proxies to your project, make sure you have:
Python 3.9+ installed
Latest Scrapy framework set up (pip install scrapy)
HypeProxies account with active proxy credentials
Basic familiarity with Scrapy spiders
If you're new to Scrapy, start with the official installation guide and tutorial on creating a project.
Get your HypeProxies credentials
HypeProxies provides unlimited bandwidth, 10 Gbps backbone infrastructure with sub-1ms latency, unlimited concurrency, and 99.9% uptime SLA. Our clean static residential proxies come from trusted U.S. carriers across all 50 states.
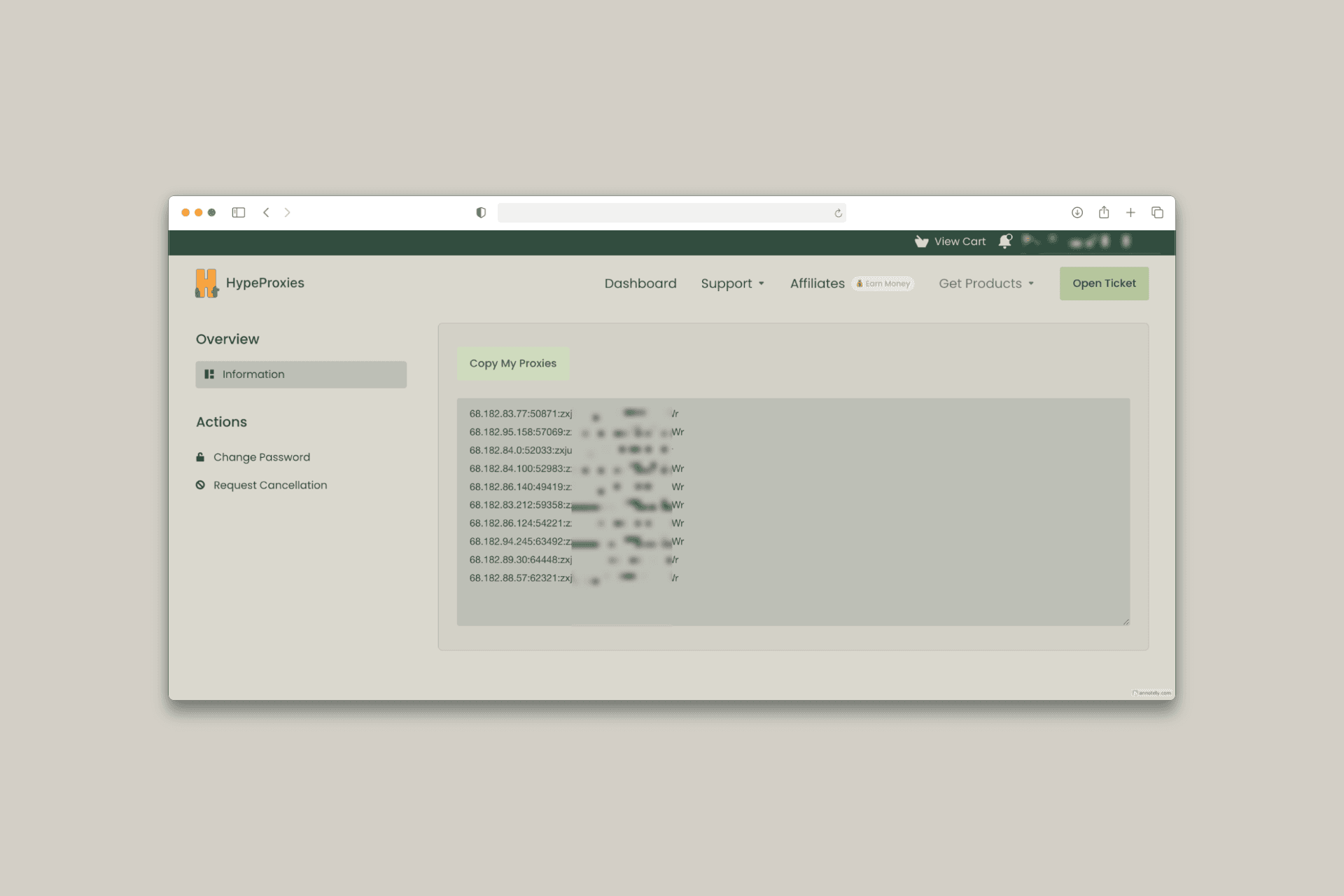
Now, to get the credential from HypeProxies, follow the steps below:
Create your HypeProxies account (submit a support ticket for a 24-hour free trial)
Select your proxy plan (ISP, Sneaker, or Ticket proxies)
Complete the checkout process
Access your proxy list from the dashboard
Note the credential format: IP:PORT:USERNAME:PASSWORD
(Optional) Test your proxy connectivity using our proxy checker tool before integrating it into your project
Method 1 – per-request configuration
To quickly test your HypeProxies setup or apply a proxy to specific requests, you can assign it inline using the meta parameter.
Replace username, password, proxy_ip, and proxy_port with your actual HypeProxies credentials.
Then run your spider: scrapy crawl proxy_test
If successful, you’ll see output like:

This spider sends a request through your proxy to a public IP checker. If everything's set up correctly, the IP in the response will be different from your local IP, confirming that your HypeProxies setup is active.
Method 2 – middleware management
If you want every request in your Scrapy project to use the same proxy, add a custom middleware:
Then activate the middleware in your settings.py:
With this setup, your spider code stays clean:
This method centralizes proxy handling – no need to manually assign the proxy for each request.
Method 3 – automatic rotation
For rotating through multiple proxies with health monitoring:
Install the rotation package:
Configure settings:
Your spider code doesn’t need to change.
The middleware automatically handles proxy selection, rotation, and health monitoring.
Next steps
Test proxy behavior with your actual target websites.
Adjust concurrency, retries, and headers based on performance.
Add error handling and monitoring for production-scale scraping.
Support resources
Proxy checker tool – test proxy connectivity and performance.
Technical support – submit tickets for technical assistance.
Community Discord – join our community for peer support.
Start building with stable, high-performance proxies today!
Share on
$1 one-time verification. Unlock your trial today.
Stay in the loop
Subscribe to our newsletter for the latest updates, product news, and more.
No spam. Unsubscribe at anytime.
Fast static residential IPs