Rotating Proxies For Web Scraping: The Operator's Guide to Unlocking Data at Scale
Your web scraping jobs are failing, and it’s burning cash. You’re hitting IP blocks, CAPTCHA walls, and wasting engineering cycles on scrapers that work one day and die the next. The root cause isn't your code; it's a flawed proxy strategy. Most guides on rotating proxies for web scraping are dangerously incomplete. They parrot basic definitions but ignore the real-world failure points: browser fingerprinting, bad ASN reputation, and sloppy rotation logic. This guide is different. We run proxy infrastructure at scale, and we’re here to explain what actually works—and what gets your entire IP pool burned.

Gunnar
Last updated -
Why Hype Proxies

What is a Rotating Proxy?
A rotating proxy is a server that assigns a new IP address to a user from a pool of available IPs for every connection or after a set duration. In practice, it’s a managed system for routing your scraper’s requests through a vast network of IPs, making your traffic appear to come from thousands of different users instead of a single server. This is the baseline requirement for any serious data acquisition project.

How Proxy Rotation Actually Works (Operator-Level)
The concept is simple, but execution is where operations fail. The choice between rotation methods dictates whether a target site sees you as a single, consistent user or a chaotic swarm of disconnected requests. Getting this wrong is the fastest way to get flagged.
Per-Request vs. Session-Based Rotation
The most critical decision is your rotation frequency. This choice defines your scraper's perceived identity and determines what kind of data you can successfully extract.
Per-Request Rotation (High-Frequency): Every single request from your scraper is sent through a different IP address. This is effective for brute-force scraping of public, stateless data—like thousands of search result pages. It makes it difficult for basic rate-limiters to track a single "user." However, attempt this on any target that requires a consistent session (e.g., a multi-step checkout process), and you will fail 100% of the time. The session cookie from request one won't match the IP of request two.
Session-Based Rotation (Sticky Sessions): This is the methodical approach. The proxy gateway assigns you a single IP that you retain for a set duration, typically 1 to 30 minutes. This "sticky" IP allows you to build a coherent user session—logging in, navigating menus, adding items to a cart. It’s essential for mimicking legitimate human behavior on complex, interactive websites. For a deeper breakdown, our guide on sticky vs rotating proxies covers the specific scenarios where each is the only viable option.
The Realities of IP Pool Management
Behind every proxy service is a massive pool of IP addresses. The quality, health, and management of this pool are what you're actually paying for.
A common failure mode is IP pool reuse. A cheap provider might hand you an IP that was just blocked by your target five minutes ago because another customer abused it. A rookie mistake is blaming the scraper when the real issue is a contaminated IP pool.
From our operational data, we see that 5-10% of any large residential proxy pool can be temporarily "dirty" or flagged for a popular target at any given moment. Effective IP management isn't about pool size; it's about constant health checks and quarantining bad IPs before they ever reach your scraper.
Concurrency and rate limits are another operational reality. Your provider caps the number of simultaneous connections you can establish. If your scraper is too aggressive and exceeds this limit, your own provider will start dropping requests. This isn't the target blocking you; it's a self-inflicted error. Finally, flawed rotation logic, like making requests within the same session that jump between IPs in different countries, is an amateur mistake that sophisticated anti-bot systems are designed to detect instantly.
Proxy Types & Tradeoffs: A Decision-Driven Breakdown
Selecting the right proxy type is a constant tradeoff between cost, speed, and success rate. There is no "best" proxy—only the right tool for the target. Making the wrong choice means wasting money and grinding your data pipeline to a halt.
Datacenter Proxies
These are IPs assigned from servers in a data center. They are extremely fast, cheap, and typically offer unmetered bandwidth, making them tempting for high-volume jobs.
When It Works: Scraping targets with weak or non-existent anti-bot protection. Think academic archives, government portals, or APIs with generous rate limits. Their speed is their primary advantage.
When It Fails: Against any moderately sophisticated target. Major e-commerce, social media, and travel sites will block datacenter IPs on sight. Their ASNs (Autonomous System Numbers) are publicly listed as commercial, which is an immediate red flag.
ISP Proxies
Also known as static residential proxies, these are IPs registered to consumer Internet Service Providers (ISPs) but hosted on datacenter servers. They offer the speed and uptime of a datacenter with the reputable ASN of a residential provider.
When It Works: Excellent for targets that block datacenter ASNs but don't deploy aggressive fingerprinting. They are the workhorses for sneaker copping, ad verification, and scraping mid-tier e-commerce sites.
When It Fails: Because they are static, high request volumes from a single ISP proxy will still trigger behavioral blocks. They also lack the IP diversity of a true residential network, making them vulnerable to subnet-level bans.
Know More: 10 Best ISP Proxies in 2026 (Ranked on Scalability, Speed & Infrastructure)
Residential Proxies
These are IPs sourced from real user devices on consumer ISPs (e.g., Comcast, Verizon). Your traffic is routed through these devices, making it appear indistinguishable from legitimate human activity.
When It Works: They are the gold standard for scraping the most heavily protected websites. Large-scale price aggregation, social media data mining, and any target employing advanced behavioral analysis require residential proxies. The massive IP diversity makes it nearly impossible to block them effectively.
When It Fails: Their primary drawback is cost and latency. Traffic is routed through real-world connections, making them slower and more expensive (typically billed per GB) than datacenter or ISP proxies. Using them on simple targets is expensive overkill.
This simple chart helps visualize the core decision you'll face: do you need a consistent session, or can you rotate with every request?
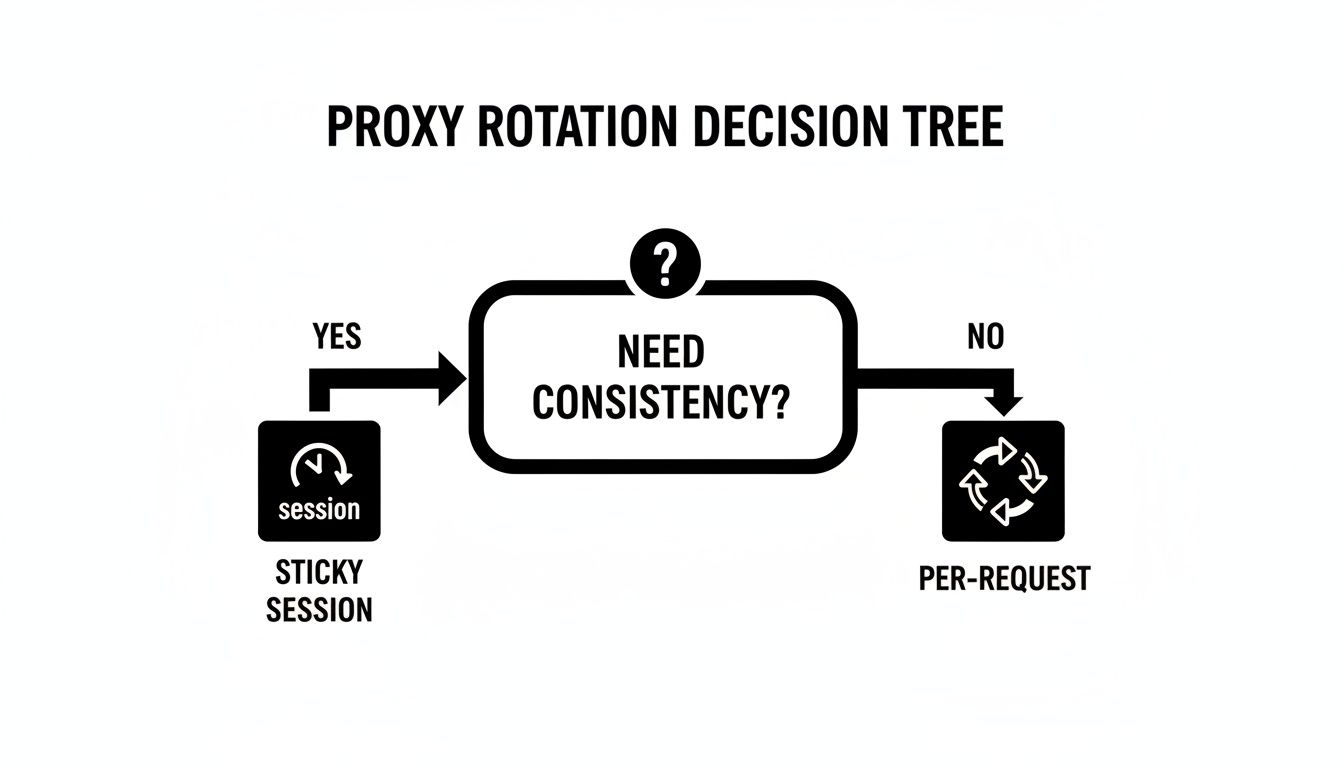
As you can see, the first question is always whether your scraping task needs a stable session or can handle rapidly changing IPs. When deciding on your proxy management strategy, you'll face a classic fork in the road: build your own system or buy a ready-made service. This decision mirrors the broader debate around custom software vs off-the-shelf solutions, where each path has its own distinct pros and cons.
Proxy Type | When It Works | When It Fails & Gets Blocked | Cost vs. Success Tradeoff |
|---|---|---|---|
Residential | Highly-protected targets (e-commerce, social media) using advanced fingerprinting and behavioral analysis. | Slower speeds and higher cost per GB can be prohibitive for massive, low-value data pulls. | Highest cost, highest success rate. The only reliable option for the toughest targets. |
ISP | Mid-tier targets that block datacenter ASNs but lack advanced bot detection. Ad-tech and retail intelligence. | High request volumes from a single static IP trigger behavioral blocks. Lacks the IP diversity to defeat subnet-level bans. | The middle ground. Faster and cheaper than residential, but far more reliable than datacenter proxies. |
Datacenter | Scraping sites with basic or no bot protection. Ideal for academic research, simple APIs, or low-competition targets. | Instantly blocked by most modern websites due to their easily identifiable commercial ASN ranges. | Lowest cost, highest speed. Lowest success rate against any moderately protected site. |
Why You’re Still Getting Blocked (Even With Rotating Proxies)
You have a premium rotating residential proxy pool, but your scrapers are still failing. Why? Because you're focusing on the IP address while anti-bot systems are analyzing your entire digital fingerprint. Believing a rotating IP makes you invisible is the single most expensive mistake a data team can make.
Modern defenses have moved beyond IP reputation. They focus on behavioral and environmental consistency. The question is no longer "Where is this request from?" but "Does this request behave like a human using a real browser?" If the signals don't align, you're blocked—regardless of your IP's quality.
Browser Fingerprinting & TLS/Client Hints
This is the primary culprit. Advanced anti-bot services execute JavaScript to collect hundreds of data points that create a unique signature of your client environment. This includes:
Canvas/WebGL Fingerprinting: The precise way your machine renders graphics creates a unique ID. Headless browsers produce distinct renderings that are trivial to flag.
TLS/JA3 Fingerprints: The initial "hello" packet in a TLS handshake has a unique signature based on the client library used. A Python
requestssignature is completely different from a Chrome browser signature.Client Hints & Header Entropy: Real browsers send a specific, ordered set of HTTP headers. Automation tools often get this wrong—sending them in the wrong order, using outdated values, or having low "entropy." This is a dead giveaway.
ASN Reputation and Bad Rotation Logic
While single IP reputation is less important, ASN reputation is critical. An ASN identifies the network provider (e.g., AWS, Comcast). A request from a known datacenter ASN is immediately more suspicious than one from a residential ISP. This is why datacenter proxies fail against tough targets; the entire network is flagged. On the hardest targets, ticket sites, that ASN check happens before anything else, which we depicted in ISP vs datacenter proxies for ticket sites.
Your own rotation logic can also be your worst enemy. If your scraper makes requests for a single user journey but pulls IPs from different countries—one from Germany, the next from Brazil—you’ve created an impossible travel scenario. This is an elementary mistake that anti-bot systems are built to catch, leading to an instant session termination. Thinking your proxies got banned is often a misdiagnosis of a much deeper fingerprinting problem.
Real-World Use Cases (With Constraints)
The right proxy strategy is entirely context-dependent. Let's examine what works—and what fails—for common scraping scenarios.
E-commerce Price and Product Data Monitoring
Why Proxies are Required: E-commerce giants like Amazon deploy sophisticated anti-bot systems to prevent price scraping. Unprotected requests are blocked almost instantly.
What Proxy Type Actually Works: High-quality rotating residential proxies are non-negotiable. You need a massive, diverse IP pool to mimic legitimate shopper traffic. Sticky sessions are mandatory for any multi-step task, like navigating from a category page to a product detail page.
What Fails at Scale: Datacenter proxies are useless. Per-request rotation will break the user session and trigger an immediate block. Challenges in areas like product price tracking really drive home the need for a solid rotating proxy setup.
What Teams Underestimate: The need to match browser fingerprints (user-agent, TLS signatures) to the IP's device profile. A request from a mobile residential IP with a desktop browser fingerprint is a clear anomaly.
SEO Rank Tracking and SERP Analysis
Why Proxies are Required: Search engines personalize results based on location and device. Scraping SERPs at scale requires making requests from thousands of different geo-locations to get accurate ranking data.
What Proxy Type Actually Works: A mix of ISP and residential proxies. ISP proxies provide the speed for high-volume, broad keyword checks. Residential proxies deliver the precise geo-targeting (down to the city level) needed for competitive local SERP analysis.
What Fails at Scale: Using a single proxy type for all queries. It's inefficient and costly. Using proxies without precise city-level targeting will return inaccurate, generic ranking data.
What Teams Underestimate: The sheer granularity of localization. Google's results can vary block by block. Without hyper-local proxies, your data is flawed.
Ad Verification and Performance Monitoring
Why Proxies are Required: Ad networks must verify that ads are displayed correctly to the target audience in specific geographic locations and on specific device types (e.g., mobile carriers).
What Proxy Type Actually Works: Rotating residential proxies with specific mobile carrier targeting are essential. The goal is to see the page exactly as a real user would on their phone.
What Fails at Scale: Any proxy pool that cannot provide clean, carrier-level IPs. Generic residential proxies are insufficient.
What Teams Underestimate: The prevalence of cloaking. Websites often serve different content to datacenter or suspicious traffic. Without a clean residential IP, you may not see the real ads at all. You can check out our solutions for web scraping proxies that offer this exact level of precision.
How to Choose the Right Setup

Moving from theory to a resilient, cost-effective pipeline requires making smart decisions upfront.
Decision Rules & Budget Guidance
Start with the cheapest viable option. Test your target with datacenter proxies first. If they fail, escalate to ISP. Only use expensive residential proxies when you have hard evidence that cheaper alternatives are being blocked.
Match proxy cost to data value. For mission-critical data from a heavily-defended site, the premium for top-tier residential proxies is a necessary business expense.
Factor in engineering overhead. A cheap, unreliable proxy service creates debugging nightmares. The cost of your team's time troubleshooting failed jobs often exceeds the savings from a low-quality provider.
When NOT to Use Rotating Proxies
Rotating proxies are the wrong tool for any task requiring a stable, persistent identity. Using them will trigger security flags and get accounts locked.
Use static, non-rotating proxies for:
Managing social media or e-commerce accounts.
Any task requiring a consistent login session from a single IP.
Interacting with services that whitelist specific IP addresses.
Common Buying Mistakes
Ignoring ASN Reputation: Buying a block of datacenter proxies from an ASN known for abuse is a waste of money. They are pre-banned on most serious targets.
Overlooking Geo-Targeting Needs: If you need location-specific data, a generic proxy pool is useless. Ensure your provider offers the granularity you require. Our guides on integrating tools like Scrapy with our proxy network detail how to configure these settings.
Mismatching Concurrency: Failing to align your scraper's concurrent connection settings with your proxy plan's limits is a common self-inflicted wound. You'll end up blocking yourself.
Success in rotating proxies for web scraping demands more than just cycling through IPs; it requires a holistic strategy to mimic human behavior from top to bottom. Without it, scrapers can face 90%+ block rates on protected sites. This challenge is precisely why the market is booming, projected to hit $16,337.5 million by 2030. This isn't just about buying IPs; it's a technological arms race. You can read the full research on the rotating proxy market to grasp the true scale of the industry.
FAQ
Are rotating proxies legal for web scraping?
Yes, using rotating proxies to scrape publicly available data is generally legal. However, legality depends on what you scrape and how you scrape it. Respect the website's robots.txt file, avoid collecting Personally Identifiable Information (PII), and ensure your scraper does not degrade the site's performance for other users. The proxy is a tool; its legal use is determined by your actions. Consult legal counsel for high-stakes projects.
What is the difference between a rotating proxy and a VPN?
A VPN is a personal privacy tool designed to secure your entire device's internet connection by routing it through a single, stable server. A rotating proxy is an infrastructure tool for automation, designed to manage thousands of IPs programmatically to enable large-scale machine traffic without being blocked. One is for human privacy; the other is for operational scale.
Why are free rotating proxies a bad idea?
Free proxies are a liability. They are notoriously unreliable, slow, and pose a significant security risk. These services are often used to inject malware, log your data for sale, or use your connection for illegal activities. The high failure rates and security vulnerabilities make them completely unsuitable for any serious data operation.
When are rotating proxies the wrong tool?
Rotating proxies are the wrong tool when your task requires a consistent, stable digital identity. For managing social media accounts, maintaining long-term login sessions, or any activity where a constantly changing IP address would appear suspicious, a static (non-rotating) proxy is the correct choice.
Ready to build a resilient and scalable web scraping infrastructure? Explore the high-performance residential and ISP proxy networks at HypeProxies and see why over 20,000 users trust us to deliver clean, fast, and reliable IPs. Get started with HypeProxies today.
Share on

$1 one-time verification. Unlock your trial today.
Stay in the loop
Subscribe to our newsletter for the latest updates, product news, and more.
No spam. Unsubscribe at anytime.




