How To Build A SEO Rank Tracker Using Python & SEO Proxies
If you do SEO rank tracking at scale, your own browser shows you only your own personalized view. Google personalizes the search results mostly by location, and to a smaller degree by your search history and the account you are signed into. Because of this, a keyword that you see at position 3 may be at position 8 for a user in another city.
Gunnar
Last updated -
Tutorials
Commercial rank trackers solve this problem, but they can get expensive. Most of them charge per keyword per day, and the bill grows quickly when you track thousands of terms across multiple locations. If you have an engineering team, you can build your own tracker. This is often cheaper, and it gives you the raw data, not only aggregated numbers. But Google aggressively blocks automated queries from a single IP, which is why most DIY trackers stop working quickly. If you send a few dozen searches from one address, you usually start to see CAPTCHAs, then 429 Too Many Requests errors, and eventually a hard block. The type of IP you route through matters as much as how you pace requests, for example many SEO teams compare options like ISP and mobile proxies before settling on a stack. Following established web scraping best practices can mitigate these infrastructure issues.
TL;DR
In 2026, scraping rank data from Google reliably takes three things that work together.
A real browser. Use camoufox, which is an anti-detect Firefox. Even patched headless Chromium gets blocked on Google.
ISP proxies. These give you the most stable IP reputation for this workload. You should spread them across diverse subnets and pace them with human-like timing.
start= pagination. Use it to page past the first 10 results, because Google removed the num=100 parameter in September 2025.
Why ISP proxies
Two questions to answer: why proxies at all, and why ISP proxies specifically.
The three forces working against you
First, Google's automated-traffic detection flags repetitive query patterns from a single IP, which is why a rank tracker that checks 500 keywords from one address gets throttled quickly. Second, search results vary by country, by region, and even by city, so a single US datacenter IP does not reliably show you how the same query ranks for a user in London. Third, logged-in sessions or sticky datacenter IPs add personalization noise. A proxy pool addresses all three. You spread your requests across many IPs (each one makes only a few queries), and you choose where those IPs are located.
Picking the right type
Proxy type is one of the most important choices here. Three families:
Proxy type
How Google sees it
Speed & stability
Block rate for SERP scraping
Datacenter
Obvious server IP, easy to flag
Very fast
High – flagged quickly
Residential
Real home ISP, peer-to-peer
Variable; rotating IPs drop mid-session
Low, but inconsistent
ISP (static residential)
Real ISP IP, hosted in a datacenter
Fast, stable
Low – and consistent
ISP proxies, which is the kind we provide at HypeProxies for SEO use cases, are the best fit for this workload. There is a common misconception that ISP proxies are a separate category from residential proxies. By the ASN that Google checks, they are not. They carry the ASN and the reputation of a real consumer ISP, and reputation databases such as MaxMind, IPinfo, IP2Location, and IPQualityScore classify them as a residential ISP, not as a datacenter.
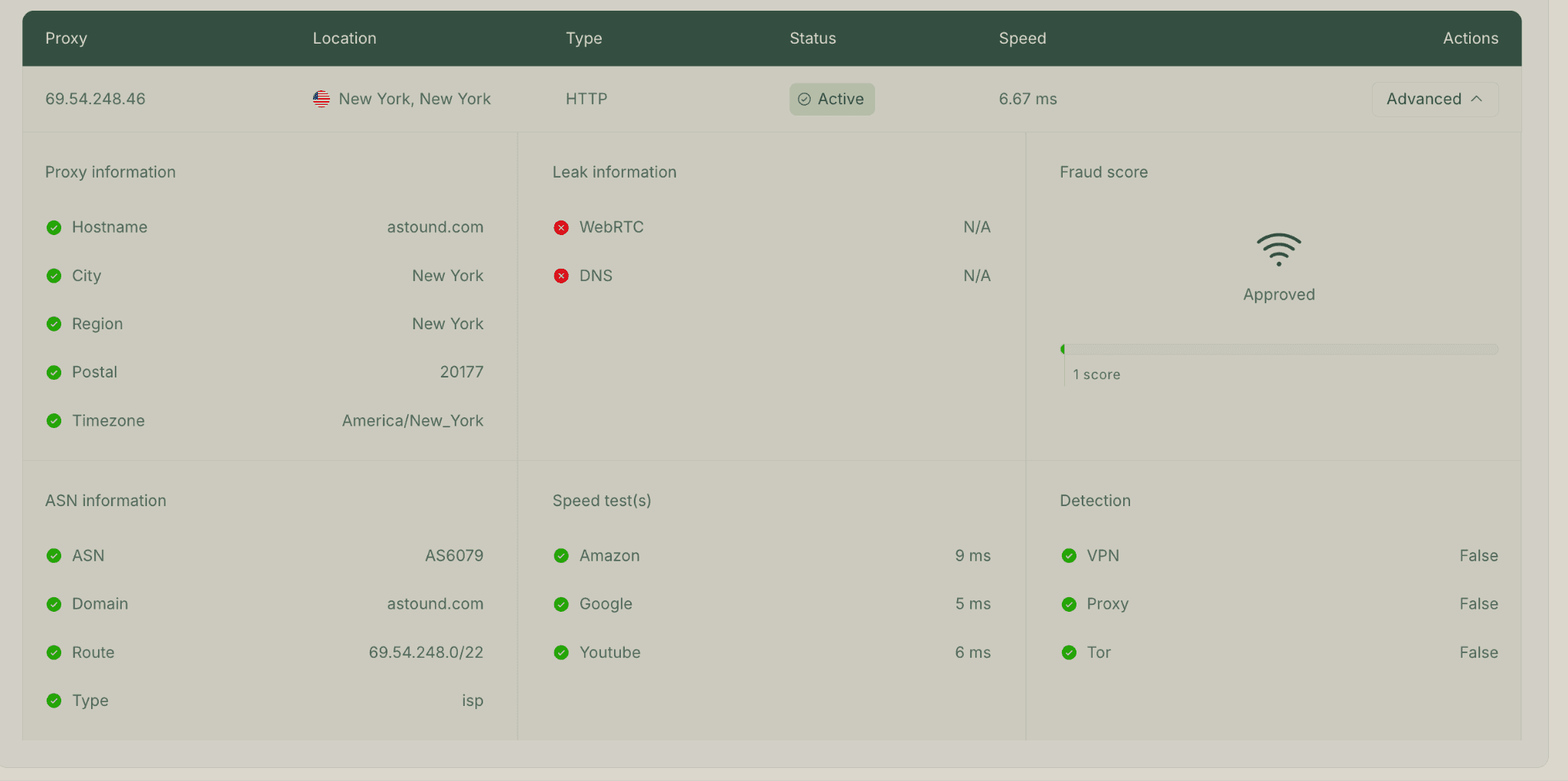
You don’t have to take our word for it: paste any IP into our free proxy checker and look at the ASN, the fraud score, and the VPN/proxy/Tor flags. Because of this classification, Google is far more likely to treat them as a residential connection. The difference is the hosting: they sit on data-center hardware, which gives them fast and stable connections. They are far less likely to drop mid-session than peer-to-peer residential IPs.
One of our production IPs in the proxy checker. The fields that matter for SERP work: hostname astound.com (Astound Broadband, a real consumer ISP), ASN AS6079, fraud score 1 out of 100, and VPN/Proxy/Tor detection all False. The 5 ms response to Google also matters, because every rank check is a full page render. This is what residential-by-ASN looks like when you check it, instead of taking a vendor's word of other proxy providers.
Concretely, this is how we run HypeProxies' SEO proxies: own racks in Ashburn, Virginia (Data Center Alley, with sub-millisecond latency to AWS and Google Cloud) and Dallas, Texas, Tier-1 carrier relationships with Verizon, Comcast, Cox, and AT&T so the IPs carry real ISP ASN reputation, and small static subnets to avoid the noisy-neighbor bans that can take whole IP ranges offline.
Tracking now requires a full headless-browser render for nearly every query. This makes each request heavier and longer-lived, so you want IPs that are both trusted and stable for the duration of a page load. If you use them correctly, ISP proxies give you a foundation Google is more likely to trust. The habits that matter most: spread your requests across enough IPs and varied subnets, and pace them with human-like timing.
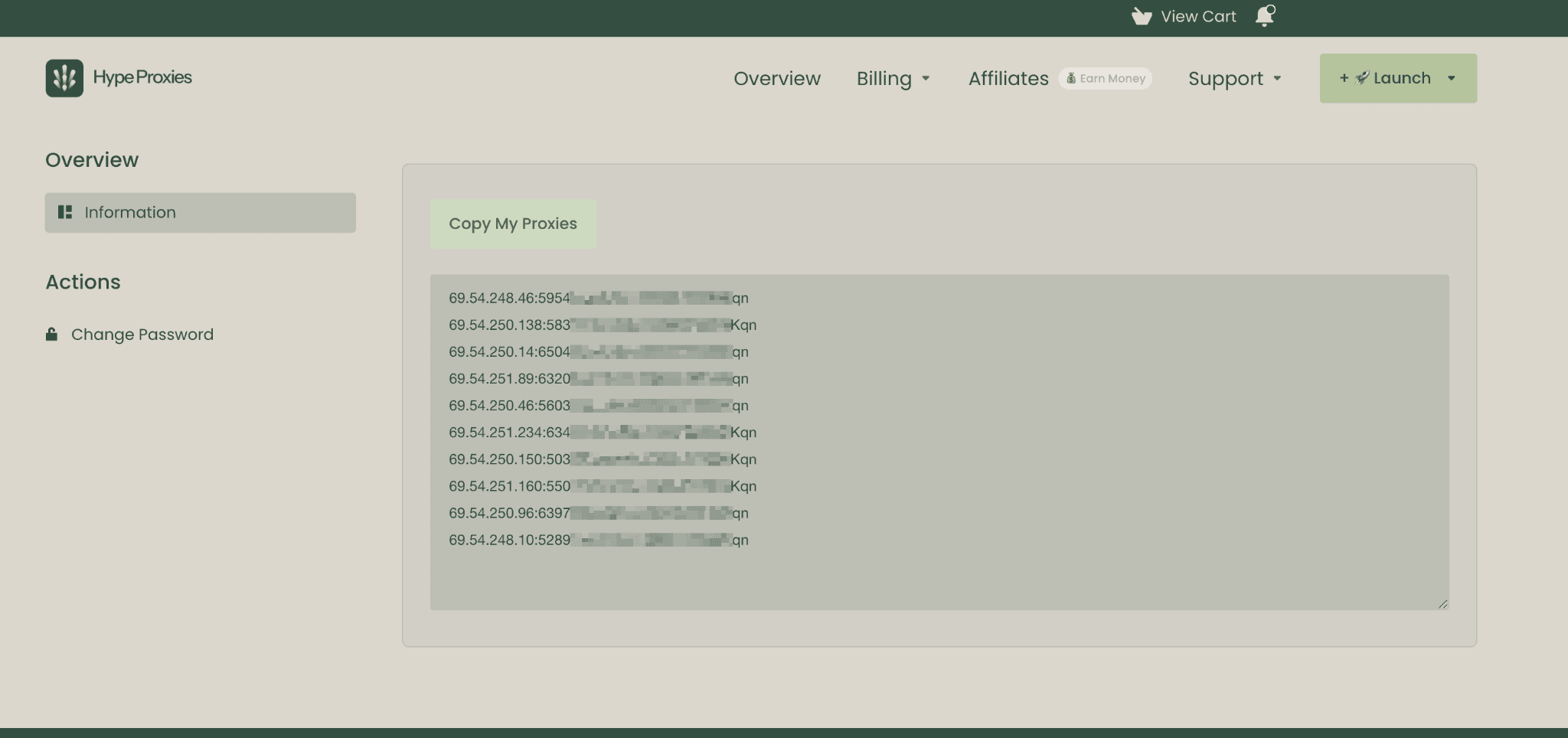
A HypeProxies ISP proxy is delivered in the standard IP:PORT:USERNAME:PASSWORD format. Here is a sample pool:
Each line is one endpoint (paste your own pool from the dashboard):
A real pool in the HypeProxies dashboard (credentials blurred). The format matches the sample above, and the subnet spread is visible in the product itself: the ten IPs span 69.54.248.x, 69.54.250.x, and 69.54.251.x. The first IP in the list, 69.54.248.46, is the same address shown in the proxy checker result earlier in this section.
What changed in 2025–2026
The old approach was simple: requests.get("https://www.google.com/search?q=...&num=100"), then parse the HTML with BeautifulSoup. Today it no longer works reliably, for two reasons.
The &num=100 parameter is dead
In September 2025, Google removed support for the &num=100 URL parameter. For years, appending it let a single request return up to 100 organic results. That was how rank trackers like Semrush, Ahrefs, and Moz, plus DIY scripts, pulled deep SERPs cheaply.
Now, that parameter is ignored. A request returns roughly 10 results. The fallout was broad: one analysis found that 77% of sites lost keyword visibility after the change. Tools that suddenly could not see beyond page 1 reported many keywords as "dropping", and the Search Console impression counts fell sharply, because the bot traffic that relied on num=100 vanished.
The fix is to use &start= for pagination. You set start=0 for results 1 to 10, start=10 for results 11 to 20, and so on. This is roughly 10× the requests for the same depth, which is why a good proxy pool is now a practical requirement for tracking at any real depth.
Google now renders results with JavaScript
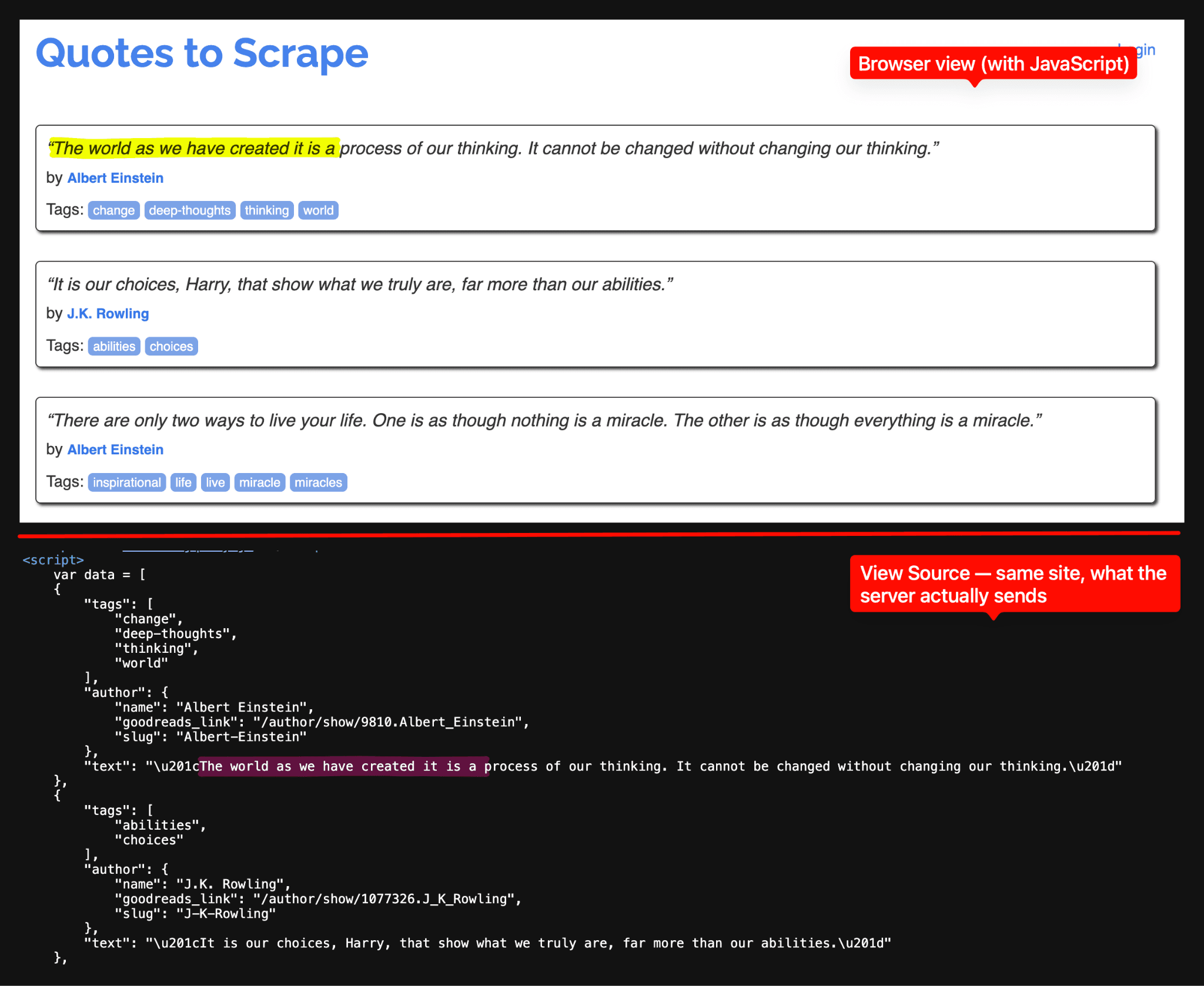
The bigger change is that Google increasingly requires JavaScript execution to render the results page. A bare HTTP GET now frequently returns a near-empty shell, a consent interstitial, or a challenge, instead of the actual SERP. The organic results, and especially the AI Overviews, are rendered by client-side JavaScript after the initial page load.
Searching for a visible quote phrase on quotes.toscrape.com/js/ shows the same text in two places – the rendered browser view at top, and inside a var data = [...] JavaScript variable in the source view at bottom. A basic HTTP scraper that does not run JavaScript sees only the <script> block, not the rendered quotes. Google's SERP relies on the same kind of client-side rendering today.
The fix here is to send requests like a real browser, not like curl. And you have to pick the right browser. You need an engine that executes Google's JavaScript and routes the requests through ISP proxies. Headless Chrome with Playwright is the usual pick. On Google, however, both vanilla and patched headless Chromium get blocked. The engine that works here is an anti-detect Firefox called camoufox. So a browser is required, but the wrong browser is still blocked.
Architecture and setup
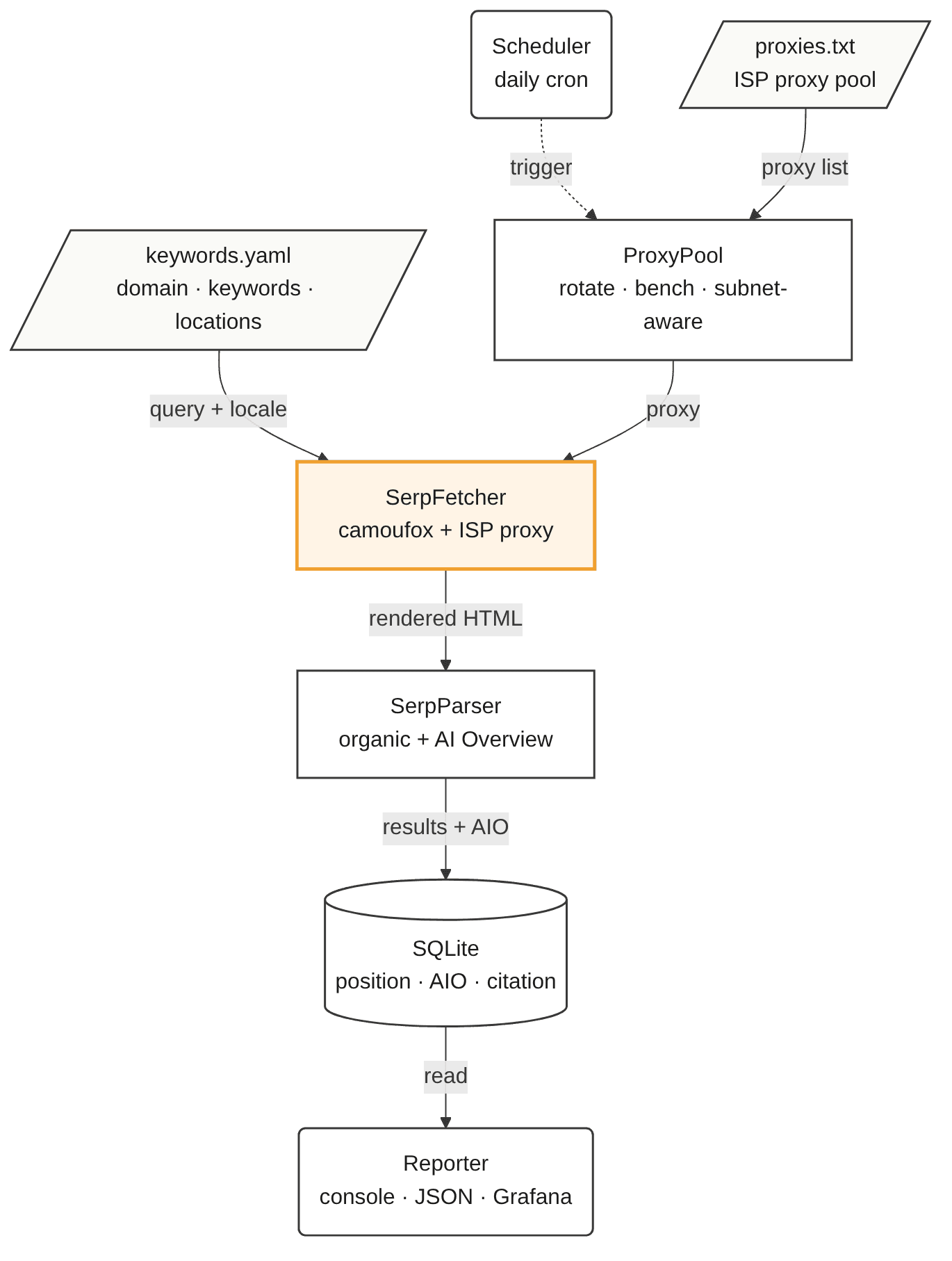
Both fixes (start= pagination and a real browser through ISP proxies) drive the build. The components:
Single top-to-bottom flow with two visual conventions: the dashed arrow is control flow (the Scheduler triggers the pipeline), and the solid arrows are data flow (config and proxy into the SerpFetcher; rendered HTML to the parser; results to storage; storage read by the reporter). SerpFetcher is highlighted because the engine choice – camoufox over Chromium – is a make-or-break decision.
Each component is a separate module, so a change in Google's HTML or a new locale setting is one file to edit, not many files in different places.
The code in this article is the readable teaching version of each module. The full repo carries a few production extras that would only clutter the explanation here: a consent-cookie helper, a sticky-session wrapper that pins one IP across a keyword's pages, and richer run summaries. The logic you see below is complete and runs on its own.
camoufox is the anti-detect Firefox that drives Google through Playwright's API; you call camoufox, not Playwright. The rest are the usual: beautifulsoup4/lxml for parsing, pyyaml for the config, apscheduler for cron, tabulate for the console table. The one-time camoufox fetch downloads the patched-Firefox binary.
target_domain:"hypeproxies.com"
max_depth:20 # max rank to check(10results = 1page render)
keywords:
- "isp proxies"
- "static residential proxy"
- "best proxies for seo"
locations:
- {label:"US",gl:"us",hl:"en"}
- {label:"UK",gl:"gb",hl:"en"}
- {label:"DE",gl:"de",hl:"en"}
target_domain:"hypeproxies.com"
max_depth:20 # max rank to check(10results = 1page render)
keywords:
- "isp proxies"
- "static residential proxy"
- "best proxies for seo"
locations:
- {label:"US",gl:"us",hl:"en"}
- {label:"UK",gl:"gb",hl:"en"}
- {label:"DE",gl:"de",hl:"en"}
target_domain:"hypeproxies.com"
max_depth:20 # max rank to check(10results = 1page render)
keywords:
- "isp proxies"
- "static residential proxy"
- "best proxies for seo"
locations:
- {label:"US",gl:"us",hl:"en"}
- {label:"UK",gl:"gb",hl:"en"}
- {label:"DE",gl:"de",hl:"en"}
gl is Google's geolocation country parameter, hl is the interface language; pair them with a same-geo proxy and you get results that closely match that location.
Proxy pool
The pool manager parses the IP:PORT:USER:PASS format, returns the fields the browser needs, rotates through the pool, and benches failing proxies.
proxy_pool.py:
"""Proxy pool manager — parses ISP proxies and rotates them."""from __future__ importannotationsimportitertoolsimportthreadingimporttimefromdataclasses importdataclassfrompathlib import Path
@dataclassclass Proxy:
host:str
port:int
username:str
password:str
failures:int = 0
benched_until:float = 0.0 # epoch seconds;0means active
@propertydef label(self) -> str:returnf"{self.host}:{self.port}"class ProxyPool:
"""Round-robin pool with simple health checks and benching."""def __init__(self,proxies: list[Proxy],bench_seconds:int = 300,max_failures:int = 3):ifnot proxies:raise ValueError("Proxy pool is empty.")self._proxies = proxiesself._cycle = itertools.cycle(proxies)self._lock = threading.Lock()self._bench_seconds = bench_secondsself._max_failures = max_failures
@classmethoddef from_file(cls,path: str | Path, **kwargs) -> "ProxyPool":"""Load 'ip:port:user:pass' lines into a pool."""
proxies:list[Proxy] = []forrawinPath(path).read_text().splitlines():line = raw.strip()ifnot line or line.startswith("#"):continueparts = line.split(":")iflen(parts) != 4:raise ValueError(f"Malformed proxy line: {line!r}")host,port,user,pwd = partsproxies.append(Proxy(host,int(port),user,pwd))returncls(proxies, **kwargs)def get(self) -> Proxy:"""Return the next active proxy, skipping benched ones."""withself._lock:now = time.time()for_inrange(len(self._proxies)):proxy = next(self._cycle)ifproxy.benched_until <= now:returnproxy
# all benched;returnthe one that recovers firstreturnmin(self._proxies,key=lambda p:p.benched_until)def report_success(self,proxy: Proxy) -> None:withself._lock:proxy.failures = 0proxy.benched_until = 0.0def report_failure(self,proxy: Proxy) -> None:withself._lock:proxy.failures += 1ifproxy.failures >= self._max_failures:proxy.benched_until = time.time() + self._bench_secondsproxy.failures = 0def stats(self) -> dict:now = time.time()active = sum(1forpinself._proxiesifp.benched_until <= now)return{"total":len(self._proxies),"active":active,"benched":len(self._proxies) - active}
"""Proxy pool manager — parses ISP proxies and rotates them."""from __future__ importannotationsimportitertoolsimportthreadingimporttimefromdataclasses importdataclassfrompathlib import Path
@dataclassclass Proxy:
host:str
port:int
username:str
password:str
failures:int = 0
benched_until:float = 0.0 # epoch seconds;0means active
@propertydef label(self) -> str:returnf"{self.host}:{self.port}"class ProxyPool:
"""Round-robin pool with simple health checks and benching."""def __init__(self,proxies: list[Proxy],bench_seconds:int = 300,max_failures:int = 3):ifnot proxies:raise ValueError("Proxy pool is empty.")self._proxies = proxiesself._cycle = itertools.cycle(proxies)self._lock = threading.Lock()self._bench_seconds = bench_secondsself._max_failures = max_failures
@classmethoddef from_file(cls,path: str | Path, **kwargs) -> "ProxyPool":"""Load 'ip:port:user:pass' lines into a pool."""
proxies:list[Proxy] = []forrawinPath(path).read_text().splitlines():line = raw.strip()ifnot line or line.startswith("#"):continueparts = line.split(":")iflen(parts) != 4:raise ValueError(f"Malformed proxy line: {line!r}")host,port,user,pwd = partsproxies.append(Proxy(host,int(port),user,pwd))returncls(proxies, **kwargs)def get(self) -> Proxy:"""Return the next active proxy, skipping benched ones."""withself._lock:now = time.time()for_inrange(len(self._proxies)):proxy = next(self._cycle)ifproxy.benched_until <= now:returnproxy
# all benched;returnthe one that recovers firstreturnmin(self._proxies,key=lambda p:p.benched_until)def report_success(self,proxy: Proxy) -> None:withself._lock:proxy.failures = 0proxy.benched_until = 0.0def report_failure(self,proxy: Proxy) -> None:withself._lock:proxy.failures += 1ifproxy.failures >= self._max_failures:proxy.benched_until = time.time() + self._bench_secondsproxy.failures = 0def stats(self) -> dict:now = time.time()active = sum(1forpinself._proxiesifp.benched_until <= now)return{"total":len(self._proxies),"active":active,"benched":len(self._proxies) - active}
"""Proxy pool manager — parses ISP proxies and rotates them."""from __future__ importannotationsimportitertoolsimportthreadingimporttimefromdataclasses importdataclassfrompathlib import Path
@dataclassclass Proxy:
host:str
port:int
username:str
password:str
failures:int = 0
benched_until:float = 0.0 # epoch seconds;0means active
@propertydef label(self) -> str:returnf"{self.host}:{self.port}"class ProxyPool:
"""Round-robin pool with simple health checks and benching."""def __init__(self,proxies: list[Proxy],bench_seconds:int = 300,max_failures:int = 3):ifnot proxies:raise ValueError("Proxy pool is empty.")self._proxies = proxiesself._cycle = itertools.cycle(proxies)self._lock = threading.Lock()self._bench_seconds = bench_secondsself._max_failures = max_failures
@classmethoddef from_file(cls,path: str | Path, **kwargs) -> "ProxyPool":"""Load 'ip:port:user:pass' lines into a pool."""
proxies:list[Proxy] = []forrawinPath(path).read_text().splitlines():line = raw.strip()ifnot line or line.startswith("#"):continueparts = line.split(":")iflen(parts) != 4:raise ValueError(f"Malformed proxy line: {line!r}")host,port,user,pwd = partsproxies.append(Proxy(host,int(port),user,pwd))returncls(proxies, **kwargs)def get(self) -> Proxy:"""Return the next active proxy, skipping benched ones."""withself._lock:now = time.time()for_inrange(len(self._proxies)):proxy = next(self._cycle)ifproxy.benched_until <= now:returnproxy
# all benched;returnthe one that recovers firstreturnmin(self._proxies,key=lambda p:p.benched_until)def report_success(self,proxy: Proxy) -> None:withself._lock:proxy.failures = 0proxy.benched_until = 0.0def report_failure(self,proxy: Proxy) -> None:withself._lock:proxy.failures += 1ifproxy.failures >= self._max_failures:proxy.benched_until = time.time() + self._bench_secondsproxy.failures = 0def stats(self) -> dict:now = time.time()active = sum(1forpinself._proxiesifp.benched_until <= now)return{"total":len(self._proxies),"active":active,"benched":len(self._proxies) - active}
The from_file() factory parses each ip:port:user:pass line into a Proxy, kept as four separate fields because the browser needs host, port, and credentials as distinct values. get() round-robins through the pool and skips benched IPs. report_failure() benches an IP for 5 minutes after 3 consecutive failures; a success resets it.
The teaching version above misses one thing: Google appears to evaluate trust at the /24 subnet level, not just per-IP, so a CAPTCHA on one address can affect its neighbors. The repo's pool spreads load across subnets and pauses an entire subnet on repeated blocks. This is also why a pool spread across many subnets works better than a pool packed into one IP range.
SERP fetcher
The fetcher renders Google with a real browser through an ISP proxy and returns the HTML. Not every browser works on Google: vanilla Playwright/Chromium gets challenged and redirected to the /sorry/ CAPTCHA. Patched variants such as Patchright and rebrowser get the same result. An independent 2026 anti-detect benchmark confirms this.
The engine that works on Google for us is camoufox: an anti-detect Firefox with C++-level fingerprint spoofing (so the fake value does not leak as an inconsistency the way a JavaScript-level patch does), a Playwright-compatible API, and native support for authenticated proxies. On the same pool where Chromium is blocked, camoufox gets through. TLS impersonation tools like curl_cffi (no browser) get only an empty JS shell from Google: JavaScript rendering is needed for reliable results, so a no-browser approach is not a dependable option for organic results.
There is also a readiness problem. Google streams in organic results progressively: a page can grow from ~125 KB to ~1.4 MB after first paint. If you read the DOM too early, you capture only some of the results (we measured 4 instead of 8) and report the wrong rank. The fetcher polls until the result count is stable, then reads.
fetcher.py (teaching version; production additions are noted after the code):
"""SERP fetcher (2026) — anti-detect Firefox (camoufox) through ISP proxies.
Plain Playwright Chromium fails on Google:both vanilla and patched headlessChromium get challenged(the /sorry/ CAPTCHA). Theengine that works is camoufox:Firefox-based,C++-level fingerprint spoofing,Playwright-compatible API,native authenticated proxies.
"""from __future__ importannotationsimportreimporturllib.parsefrom camoufox.sync_apiimportCamoufox
# Text on Google's EU consent buttons (varies by locale).
CONSENT_RE = r"^(Accept all|I agree|Reject all|Alle akzeptieren|Tout accepter)$"
# Counts result links currentlyinthe DOM. Usedonly to detect when results
# stop arriving;the real parse happens later.
COUNT_JS = "document.querySelectorAll("#rsoa h3,#searcha h3").length"class BlockedError(Exception):"""Google returned a CAPTCHA / 'unusual traffic' wall."""class FetchError(Exception):"""A transport/render failure worth retrying."""def _build_url(query, *,start=0,gl="us",hl="en"):
# `num`was deprecated by Google on 2025-09-11;paginate with`start`.
params = {"q":query,"start":start,"gl":gl,"hl":hl,"pws":"0"}return"https://www.google.com/search?" + urllib.parse.urlencode(params)def _proxy(p):
# camoufox takes the same {server,username,password}dict Playwright does.
return{"server":f"http://{p.host}:{p.port}","username":p.username,"password":p.password}class SerpFetcher:
def __init__(self,pool, *,headless=True):self.pool = poolself.headless = headlessdef __enter__(self):returnselfdef __exit__(self, *exc):returnFalsedef _settle(self,page):"""Readiness gate. Google streams in results progressively, so reading the DOM
too early under-counts and reports the wrong rank. Polluntil the resultcount is stable across two consecutive checks,then read the DOM."""page.mouse.wheel(0,2200) # scroll to trigger lazy-loadlast,stable = -1,0for_inrange(20): # up to ~10spage.wait_for_timeout(500)n = page.evaluate(COUNT_JS)ifn and n == last:stable += 1ifstable >= 2:breakelse:stable,last = 0,nreturnpage.content()def fetch_page(self,query, *,start=0,gl="us",hl="en"):proxy = self.pool.get()
# One anti-detect Firefox per query,pinned to one proxy.
# humanize=True:human-like cursor movement(anti-bot signal).
try:withCamoufox(headless=self.headless,proxy=_proxy(proxy),locale=f"{hl}-{gl.upper()}",humanize=True)as browser:page = browser.new_page()page.goto(_build_url(query,start=start,gl=gl,hl=hl),wait_until="domcontentloaded",timeout=30000)if"/sorry/"inpage.url: # CAPTCHA wallraise BlockedError(f"blocked via {proxy.label}")try: # tryto dismiss EU consent popupbtn = page.get_by_role("button",name=re.compile(CONSENT_RE)).firstifbtn.is_visible(timeout=2500):btn.click()except Exception:pass
# If results container does not appearintime,raise FetchError below.
page.wait_for_selector("#search, #rso",timeout=8000)html = self._settle(page) # wait forall results to loadexcept BlockedError:self.pool.report_failure(proxy)raiseexcept Exceptionas exc: # timeout / soft block / renderself.pool.report_failure(proxy)raise FetchError(f"render failed via {proxy.label}: {exc}")from excself.pool.report_success(proxy)returnhtml
"""SERP fetcher (2026) — anti-detect Firefox (camoufox) through ISP proxies.
Plain Playwright Chromium fails on Google:both vanilla and patched headlessChromium get challenged(the /sorry/ CAPTCHA). Theengine that works is camoufox:Firefox-based,C++-level fingerprint spoofing,Playwright-compatible API,native authenticated proxies.
"""from __future__ importannotationsimportreimporturllib.parsefrom camoufox.sync_apiimportCamoufox
# Text on Google's EU consent buttons (varies by locale).
CONSENT_RE = r"^(Accept all|I agree|Reject all|Alle akzeptieren|Tout accepter)$"
# Counts result links currentlyinthe DOM. Usedonly to detect when results
# stop arriving;the real parse happens later.
COUNT_JS = "document.querySelectorAll("#rsoa h3,#searcha h3").length"class BlockedError(Exception):"""Google returned a CAPTCHA / 'unusual traffic' wall."""class FetchError(Exception):"""A transport/render failure worth retrying."""def _build_url(query, *,start=0,gl="us",hl="en"):
# `num`was deprecated by Google on 2025-09-11;paginate with`start`.
params = {"q":query,"start":start,"gl":gl,"hl":hl,"pws":"0"}return"https://www.google.com/search?" + urllib.parse.urlencode(params)def _proxy(p):
# camoufox takes the same {server,username,password}dict Playwright does.
return{"server":f"http://{p.host}:{p.port}","username":p.username,"password":p.password}class SerpFetcher:
def __init__(self,pool, *,headless=True):self.pool = poolself.headless = headlessdef __enter__(self):returnselfdef __exit__(self, *exc):returnFalsedef _settle(self,page):"""Readiness gate. Google streams in results progressively, so reading the DOM
too early under-counts and reports the wrong rank. Polluntil the resultcount is stable across two consecutive checks,then read the DOM."""page.mouse.wheel(0,2200) # scroll to trigger lazy-loadlast,stable = -1,0for_inrange(20): # up to ~10spage.wait_for_timeout(500)n = page.evaluate(COUNT_JS)ifn and n == last:stable += 1ifstable >= 2:breakelse:stable,last = 0,nreturnpage.content()def fetch_page(self,query, *,start=0,gl="us",hl="en"):proxy = self.pool.get()
# One anti-detect Firefox per query,pinned to one proxy.
# humanize=True:human-like cursor movement(anti-bot signal).
try:withCamoufox(headless=self.headless,proxy=_proxy(proxy),locale=f"{hl}-{gl.upper()}",humanize=True)as browser:page = browser.new_page()page.goto(_build_url(query,start=start,gl=gl,hl=hl),wait_until="domcontentloaded",timeout=30000)if"/sorry/"inpage.url: # CAPTCHA wallraise BlockedError(f"blocked via {proxy.label}")try: # tryto dismiss EU consent popupbtn = page.get_by_role("button",name=re.compile(CONSENT_RE)).firstifbtn.is_visible(timeout=2500):btn.click()except Exception:pass
# If results container does not appearintime,raise FetchError below.
page.wait_for_selector("#search, #rso",timeout=8000)html = self._settle(page) # wait forall results to loadexcept BlockedError:self.pool.report_failure(proxy)raiseexcept Exceptionas exc: # timeout / soft block / renderself.pool.report_failure(proxy)raise FetchError(f"render failed via {proxy.label}: {exc}")from excself.pool.report_success(proxy)returnhtml
"""SERP fetcher (2026) — anti-detect Firefox (camoufox) through ISP proxies.
Plain Playwright Chromium fails on Google:both vanilla and patched headlessChromium get challenged(the /sorry/ CAPTCHA). Theengine that works is camoufox:Firefox-based,C++-level fingerprint spoofing,Playwright-compatible API,native authenticated proxies.
"""from __future__ importannotationsimportreimporturllib.parsefrom camoufox.sync_apiimportCamoufox
# Text on Google's EU consent buttons (varies by locale).
CONSENT_RE = r"^(Accept all|I agree|Reject all|Alle akzeptieren|Tout accepter)$"
# Counts result links currentlyinthe DOM. Usedonly to detect when results
# stop arriving;the real parse happens later.
COUNT_JS = "document.querySelectorAll("#rsoa h3,#searcha h3").length"class BlockedError(Exception):"""Google returned a CAPTCHA / 'unusual traffic' wall."""class FetchError(Exception):"""A transport/render failure worth retrying."""def _build_url(query, *,start=0,gl="us",hl="en"):
# `num`was deprecated by Google on 2025-09-11;paginate with`start`.
params = {"q":query,"start":start,"gl":gl,"hl":hl,"pws":"0"}return"https://www.google.com/search?" + urllib.parse.urlencode(params)def _proxy(p):
# camoufox takes the same {server,username,password}dict Playwright does.
return{"server":f"http://{p.host}:{p.port}","username":p.username,"password":p.password}class SerpFetcher:
def __init__(self,pool, *,headless=True):self.pool = poolself.headless = headlessdef __enter__(self):returnselfdef __exit__(self, *exc):returnFalsedef _settle(self,page):"""Readiness gate. Google streams in results progressively, so reading the DOM
too early under-counts and reports the wrong rank. Polluntil the resultcount is stable across two consecutive checks,then read the DOM."""page.mouse.wheel(0,2200) # scroll to trigger lazy-loadlast,stable = -1,0for_inrange(20): # up to ~10spage.wait_for_timeout(500)n = page.evaluate(COUNT_JS)ifn and n == last:stable += 1ifstable >= 2:breakelse:stable,last = 0,nreturnpage.content()def fetch_page(self,query, *,start=0,gl="us",hl="en"):proxy = self.pool.get()
# One anti-detect Firefox per query,pinned to one proxy.
# humanize=True:human-like cursor movement(anti-bot signal).
try:withCamoufox(headless=self.headless,proxy=_proxy(proxy),locale=f"{hl}-{gl.upper()}",humanize=True)as browser:page = browser.new_page()page.goto(_build_url(query,start=start,gl=gl,hl=hl),wait_until="domcontentloaded",timeout=30000)if"/sorry/"inpage.url: # CAPTCHA wallraise BlockedError(f"blocked via {proxy.label}")try: # tryto dismiss EU consent popupbtn = page.get_by_role("button",name=re.compile(CONSENT_RE)).firstifbtn.is_visible(timeout=2500):btn.click()except Exception:pass
# If results container does not appearintime,raise FetchError below.
page.wait_for_selector("#search, #rso",timeout=8000)html = self._settle(page) # wait forall results to loadexcept BlockedError:self.pool.report_failure(proxy)raiseexcept Exceptionas exc: # timeout / soft block / renderself.pool.report_failure(proxy)raise FetchError(f"render failed via {proxy.label}: {exc}")from excself.pool.report_success(proxy)returnhtml
Two choices matter most. The readiness gate (_settle) polls until the result count is stable; without it you capture 4 results when 8 exist and silently report the wrong rank. The locale match sets the browser language from gl/hl so a German-located proxy is presented as a German visitor, so Google sees one consistent identity instead of a mismatch. The rest is configuration. humanize=True makes cursor movement look human; instant, no-cursor page loads are detectable even with a clean fingerprint. The URL builder skips the removed num parameter and paginates with start=0, 10, 20, …. Camoufox accepts the same {server, username, password} proxy dict as Playwright.
Tip: while debugging, pass headless=False to SerpFetcher(pool, headless=False) to watch the browser run. The fastest way to spot a consent wall or a block.
Status codes lie
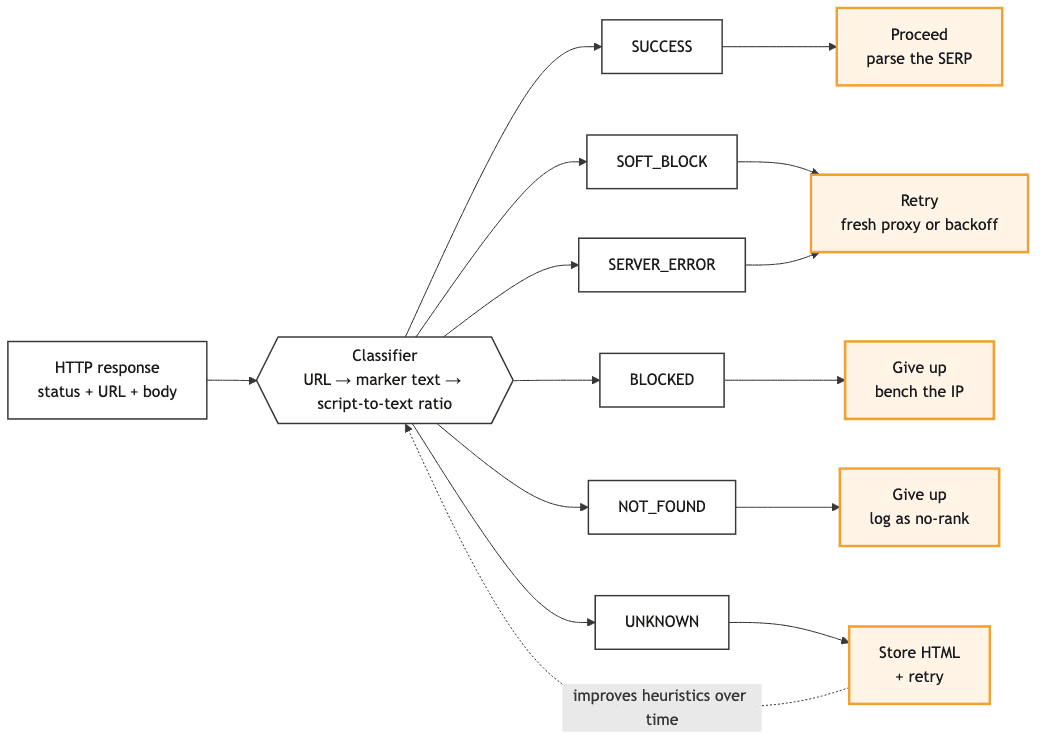
A SERP that returns HTTP 200 might be a challenge page, an empty shell, or a genuine "no results". The repo never branches on the status code alone. Instead, a response classifier sorts each render into one of 6 terminal states (SUCCESS, BLOCKED, SOFT_BLOCK, NOT_FOUND, SERVER_ERROR, UNKNOWN) using cheap heuristics first (URL, marker text) then a heavier signal (script-to-text ratio). Each state maps to a distinct action (proceed / retry / give up); unrecognized pages get written to disk so the heuristics improve from real evidence.
In practice, BLOCKED and SUCCESS are the two states you will see constantly, and the others are the safety net. Modern Google almost always returns a results container even for a weak query, so a true "no results" page is rare; when your keyword does not rank, that surfaces as a SUCCESS page which then parses to zero organic results, and the tracker handles it downstream as "not ranked". The value of the other states is that on the day Google does serve you a shell or an error, the tracker retries or backs off instead of recording a false zero.
Six terminal states, four actions. The dashed feedback loop is what makes the classifier improve over time: every unrecognized page becomes new evidence the heuristics can learn from. A naive if status_code == 200: parse(html) collapses all six outcomes into one.
Sticky sessions, not per-request rotation
The teaching version above uses a fresh IP for every page, so one keyword with 3 pages uses 3 IPs and triggers the consent wall 3 times. This is how rotating residential proxies are used, but it wastes the ISP-proxy advantage. When evaluatingsticky vs rotating proxies, a sticky profile is significantly better here: the repo's sticky session pins one IP and one browser context across all pages of a keyword. Rotation happens between keywords, with a fresh IP only if the pinned one is blocked.
Loaded fine, but wrong
A clean HTTP 200 with real results is not the same as the results you asked for. The silent corruptions to watch for:
"Did you mean…" auto-corrections. Google rewrites your query without notice and returns results for a different term. Your tracker reports "isp proxys" at rank 4, but that rank is for "isp proxies".
Locale override. Cookie-based or IP-based geo guessing returns German results despite gl=us. The fix is to assert the locale you expect (page language, currency symbols) before trusting the rank.
Featured snippet takes position 1. A snippet box (sometimes called "position 0") moves the visual rank-1 organic result one position lower. If your rank changes from 1 to 2 overnight, the cause may be a new snippet, not a real rank drop.
Empty results for typos. A misspelled brand name returns 0 organic results. Without the parse-failure triage in the tracker loop below, this looks like "you lost all rankings".
The classifier above catches the obvious failures; these are the silent ones. The solution is the same: check for positive signals (expected language tokens, result count above a threshold, query echoed in the page) instead of only the absence of a CAPTCHA.
SERP parser
From the rendered HTML we extract the organic results and find the position of the target domain. Google's HTML changes often, so we parse defensively: we use the more stable structure (the title link element) inside the main results column, and we exclude anything inside the AI Overview block.
parser.py:
"""SERP parser (2026): parses a rendered Google page into organic results,
AI-Overview presence,and the domains the AI Overview cites.
Theparser anchors on the title-link structure(`a h3`)inside the main resultscontainer(`#rso` / `#search`). Thisstructure has been more stable acrossGoogle's redesigns than CSS class names like `.g`, which change often. Links
inside the AI Overview block are excluded from the organic count and returnedseparately,so the caller can check whether a given domain is cited there.
"""
from __future__ importannotationsimporturllib.parsefrom dataclasses importdataclassfrombs4 import BeautifulSoup
# Visible AI-Overview heading text,one entry per UI language(verified en,de).
AI_OVERVIEW_MARKERS = ("AI Overview","Generative AI is experimental","AI-powered overview","Übersicht mit KI")
# Language-independent anchor:the AIO card carries these jscontroller values
# across locales(Google rotates them over time,so we pair both signals).
AI_OVERVIEW_CONTROLLERS = ("AkrxPe","EYwa3d")
# UI languages where AIO detection is verified. Thetracker warns forany other
# locale,so a silent missina newlanguage is visible instead of invisible.
AIO_VALIDATED_LOCALES = ("en","de")
@dataclassclass OrganicResult:
position:int
title:str
url:str
domain:str
@dataclassclass SerpResult:
organic:list[OrganicResult]
ai_overview:bool #is an AI Overview present?
ai_overview_domains: list[str] # domains cited inside the AI Overviewdef _clean_google_url(href: str) -> str | None:"""Google sometimes wraps links as /url?q=<real>&...; unwrap them."""ifhref.startswith("/url?"):qs = urllib.parse.parse_qs(urllib.parse.urlparse(href).query)returnqs.get("q",[None])[0]ifhref.startswith("http"):returnhrefreturnNonedef _domain_of(url: str) -> str:netloc = urllib.parse.urlparse(url).netloc.lower()returnnetloc[4:]ifnetloc.startswith("www.")elsenetlocdef _norm_target(target_domain: str) -> str:t = target_domain.lower()returnt[4:]ift.startswith("www.")elsetdef _aio_controller_el(soup: BeautifulSoup):"""The AIO card by its language-independent jscontroller, or None."""forjcinAI_OVERVIEW_CONTROLLERS:forelinsoup.find_all(attrs={"jscontroller":jc}):ifnot(el.select_one("#rso")or el.select_one("#search")):returnelreturnNonedef _has_ai_overview(soup: BeautifulSoup) -> bool:
# Two independent signals:visible heading text,or the structural anchor —
# so detection survives a locale change or a jscontroller rotation.
text = soup.get_text(" ",strip=True)ifany(markerintext formarker inAI_OVERVIEW_MARKERS):returnTruereturn_aio_controller_el(soup)is not Nonedef _external_citation_urls(node) -> set[str]:
urls:set[str] = set()forainnode.find_all("a",href=True):cleaned = _clean_google_url(str(a["href"]))ifcleaned and "google."notin_domain_of(cleaned):urls.add(cleaned)returnurlsdef _aio_block(soup: BeautifulSoup):"""The AI-Overview card element, or None. Google no longer wraps the AI
Overviewina stable`aria-label`/`role`container. Strategy1(worksinany
language):find the card by its jscontroller. Strategy2(fallback):anchoron the visible heading text,then climb to the card by walking up whiletheset of external citation domains stays the same — stopping before the climbreaches the organic results(`#rso`/`#search`)or a neighbouring feature."""
el = _aio_controller_el(soup)ifel is not None and _external_citation_urls(el):returnelheading = NoneformarkerinAI_OVERVIEW_MARKERS:node = soup.find(string=lambda s:s is not None and s.strip() == marker)ifnode is not None:heading = node.parentbreakifheading is None:returnNoneblock,cur,plateau = heading,heading,Nonefor_inrange(20):cur = cur.parentifcur is None or cur.select_one("#rso")or cur.select_one("#search"):breakurls = _external_citation_urls(cur)ifnot urls:block = curelif plateau is None or urls == plateau:plateau,block = urls,curelse:breakreturnblockdef _organic_from_soup(soup,aio_block,*,start_rank:int):
# Scope to the main results column;fall back to the whole doc ifneeded.
container = soup.select_one("#rso")or soup.select_one("#search")or soup
results:list[OrganicResult] = []
seen:set[str] = set()rank = start_rankforh3incontainer.select("a h3"):anchor = h3.find_parent("a")ifnot anchor or not anchor.get("href"):continue
# Exclude AI-Overview citation links by DOM containment,not by URL:a
# page can be both AIO-cited and organically ranked,and the organic
# result must still count.
ifaio_block is not None and aio_blockinanchor.parents:continueurl = _clean_google_url(str(anchor["href"]))ifnot url:continuedomain = _domain_of(url)ifnot domain or "google."indomain or urlinseen:continueseen.add(url)results.append(OrganicResult(rank,h3.get_text(strip=True),url,domain))rank += 1returnresultsdef parse_serp(html: str,*,start_rank:int = 1) -> SerpResult:"""Parse one rendered SERP page into organic results, AI-Overview presence,
and the domains it cites. `start_rank` offsets positions when paginating."""
soup = BeautifulSoup(html, "lxml")
block = _aio_block(soup)
aio_urls = _external_citation_urls(block) if block is not None else set()
aio_domains = sorted({d for d in (_domain_of(u) for u in aio_urls) if d})
return SerpResult(
organic=_organic_from_soup(soup, block, start_rank=start_rank),
ai_overview=_has_ai_overview(soup),
ai_overview_domains=aio_domains,
)
def find_rank(results: list[OrganicResult], target_domain: str):
"""First organic result matching target_domain (or a subdomain), or None."""
target = _norm_target(target_domain)
for r in results:
if r.domain == target or r.domain.endswith("." + target):
return r
return None
def domain_cited(domains: list[str], target_domain: str) -> bool:
"""True if target_domain (or a subdomain) is cited in the AI Overview."""
target = _norm_target(target_domain)
return any(d == target or d.endswith("." + target) for d in domains)
"""SERP parser (2026): parses a rendered Google page into organic results,
AI-Overview presence,and the domains the AI Overview cites.
Theparser anchors on the title-link structure(`a h3`)inside the main resultscontainer(`#rso` / `#search`). Thisstructure has been more stable acrossGoogle's redesigns than CSS class names like `.g`, which change often. Links
inside the AI Overview block are excluded from the organic count and returnedseparately,so the caller can check whether a given domain is cited there.
"""
from __future__ importannotationsimporturllib.parsefrom dataclasses importdataclassfrombs4 import BeautifulSoup
# Visible AI-Overview heading text,one entry per UI language(verified en,de).
AI_OVERVIEW_MARKERS = ("AI Overview","Generative AI is experimental","AI-powered overview","Übersicht mit KI")
# Language-independent anchor:the AIO card carries these jscontroller values
# across locales(Google rotates them over time,so we pair both signals).
AI_OVERVIEW_CONTROLLERS = ("AkrxPe","EYwa3d")
# UI languages where AIO detection is verified. Thetracker warns forany other
# locale,so a silent missina newlanguage is visible instead of invisible.
AIO_VALIDATED_LOCALES = ("en","de")
@dataclassclass OrganicResult:
position:int
title:str
url:str
domain:str
@dataclassclass SerpResult:
organic:list[OrganicResult]
ai_overview:bool #is an AI Overview present?
ai_overview_domains: list[str] # domains cited inside the AI Overviewdef _clean_google_url(href: str) -> str | None:"""Google sometimes wraps links as /url?q=<real>&...; unwrap them."""ifhref.startswith("/url?"):qs = urllib.parse.parse_qs(urllib.parse.urlparse(href).query)returnqs.get("q",[None])[0]ifhref.startswith("http"):returnhrefreturnNonedef _domain_of(url: str) -> str:netloc = urllib.parse.urlparse(url).netloc.lower()returnnetloc[4:]ifnetloc.startswith("www.")elsenetlocdef _norm_target(target_domain: str) -> str:t = target_domain.lower()returnt[4:]ift.startswith("www.")elsetdef _aio_controller_el(soup: BeautifulSoup):"""The AIO card by its language-independent jscontroller, or None."""forjcinAI_OVERVIEW_CONTROLLERS:forelinsoup.find_all(attrs={"jscontroller":jc}):ifnot(el.select_one("#rso")or el.select_one("#search")):returnelreturnNonedef _has_ai_overview(soup: BeautifulSoup) -> bool:
# Two independent signals:visible heading text,or the structural anchor —
# so detection survives a locale change or a jscontroller rotation.
text = soup.get_text(" ",strip=True)ifany(markerintext formarker inAI_OVERVIEW_MARKERS):returnTruereturn_aio_controller_el(soup)is not Nonedef _external_citation_urls(node) -> set[str]:
urls:set[str] = set()forainnode.find_all("a",href=True):cleaned = _clean_google_url(str(a["href"]))ifcleaned and "google."notin_domain_of(cleaned):urls.add(cleaned)returnurlsdef _aio_block(soup: BeautifulSoup):"""The AI-Overview card element, or None. Google no longer wraps the AI
Overviewina stable`aria-label`/`role`container. Strategy1(worksinany
language):find the card by its jscontroller. Strategy2(fallback):anchoron the visible heading text,then climb to the card by walking up whiletheset of external citation domains stays the same — stopping before the climbreaches the organic results(`#rso`/`#search`)or a neighbouring feature."""
el = _aio_controller_el(soup)ifel is not None and _external_citation_urls(el):returnelheading = NoneformarkerinAI_OVERVIEW_MARKERS:node = soup.find(string=lambda s:s is not None and s.strip() == marker)ifnode is not None:heading = node.parentbreakifheading is None:returnNoneblock,cur,plateau = heading,heading,Nonefor_inrange(20):cur = cur.parentifcur is None or cur.select_one("#rso")or cur.select_one("#search"):breakurls = _external_citation_urls(cur)ifnot urls:block = curelif plateau is None or urls == plateau:plateau,block = urls,curelse:breakreturnblockdef _organic_from_soup(soup,aio_block,*,start_rank:int):
# Scope to the main results column;fall back to the whole doc ifneeded.
container = soup.select_one("#rso")or soup.select_one("#search")or soup
results:list[OrganicResult] = []
seen:set[str] = set()rank = start_rankforh3incontainer.select("a h3"):anchor = h3.find_parent("a")ifnot anchor or not anchor.get("href"):continue
# Exclude AI-Overview citation links by DOM containment,not by URL:a
# page can be both AIO-cited and organically ranked,and the organic
# result must still count.
ifaio_block is not None and aio_blockinanchor.parents:continueurl = _clean_google_url(str(anchor["href"]))ifnot url:continuedomain = _domain_of(url)ifnot domain or "google."indomain or urlinseen:continueseen.add(url)results.append(OrganicResult(rank,h3.get_text(strip=True),url,domain))rank += 1returnresultsdef parse_serp(html: str,*,start_rank:int = 1) -> SerpResult:"""Parse one rendered SERP page into organic results, AI-Overview presence,
and the domains it cites. `start_rank` offsets positions when paginating."""
soup = BeautifulSoup(html, "lxml")
block = _aio_block(soup)
aio_urls = _external_citation_urls(block) if block is not None else set()
aio_domains = sorted({d for d in (_domain_of(u) for u in aio_urls) if d})
return SerpResult(
organic=_organic_from_soup(soup, block, start_rank=start_rank),
ai_overview=_has_ai_overview(soup),
ai_overview_domains=aio_domains,
)
def find_rank(results: list[OrganicResult], target_domain: str):
"""First organic result matching target_domain (or a subdomain), or None."""
target = _norm_target(target_domain)
for r in results:
if r.domain == target or r.domain.endswith("." + target):
return r
return None
def domain_cited(domains: list[str], target_domain: str) -> bool:
"""True if target_domain (or a subdomain) is cited in the AI Overview."""
target = _norm_target(target_domain)
return any(d == target or d.endswith("." + target) for d in domains)
"""SERP parser (2026): parses a rendered Google page into organic results,
AI-Overview presence,and the domains the AI Overview cites.
Theparser anchors on the title-link structure(`a h3`)inside the main resultscontainer(`#rso` / `#search`). Thisstructure has been more stable acrossGoogle's redesigns than CSS class names like `.g`, which change often. Links
inside the AI Overview block are excluded from the organic count and returnedseparately,so the caller can check whether a given domain is cited there.
"""
from __future__ importannotationsimporturllib.parsefrom dataclasses importdataclassfrombs4 import BeautifulSoup
# Visible AI-Overview heading text,one entry per UI language(verified en,de).
AI_OVERVIEW_MARKERS = ("AI Overview","Generative AI is experimental","AI-powered overview","Übersicht mit KI")
# Language-independent anchor:the AIO card carries these jscontroller values
# across locales(Google rotates them over time,so we pair both signals).
AI_OVERVIEW_CONTROLLERS = ("AkrxPe","EYwa3d")
# UI languages where AIO detection is verified. Thetracker warns forany other
# locale,so a silent missina newlanguage is visible instead of invisible.
AIO_VALIDATED_LOCALES = ("en","de")
@dataclassclass OrganicResult:
position:int
title:str
url:str
domain:str
@dataclassclass SerpResult:
organic:list[OrganicResult]
ai_overview:bool #is an AI Overview present?
ai_overview_domains: list[str] # domains cited inside the AI Overviewdef _clean_google_url(href: str) -> str | None:"""Google sometimes wraps links as /url?q=<real>&...; unwrap them."""ifhref.startswith("/url?"):qs = urllib.parse.parse_qs(urllib.parse.urlparse(href).query)returnqs.get("q",[None])[0]ifhref.startswith("http"):returnhrefreturnNonedef _domain_of(url: str) -> str:netloc = urllib.parse.urlparse(url).netloc.lower()returnnetloc[4:]ifnetloc.startswith("www.")elsenetlocdef _norm_target(target_domain: str) -> str:t = target_domain.lower()returnt[4:]ift.startswith("www.")elsetdef _aio_controller_el(soup: BeautifulSoup):"""The AIO card by its language-independent jscontroller, or None."""forjcinAI_OVERVIEW_CONTROLLERS:forelinsoup.find_all(attrs={"jscontroller":jc}):ifnot(el.select_one("#rso")or el.select_one("#search")):returnelreturnNonedef _has_ai_overview(soup: BeautifulSoup) -> bool:
# Two independent signals:visible heading text,or the structural anchor —
# so detection survives a locale change or a jscontroller rotation.
text = soup.get_text(" ",strip=True)ifany(markerintext formarker inAI_OVERVIEW_MARKERS):returnTruereturn_aio_controller_el(soup)is not Nonedef _external_citation_urls(node) -> set[str]:
urls:set[str] = set()forainnode.find_all("a",href=True):cleaned = _clean_google_url(str(a["href"]))ifcleaned and "google."notin_domain_of(cleaned):urls.add(cleaned)returnurlsdef _aio_block(soup: BeautifulSoup):"""The AI-Overview card element, or None. Google no longer wraps the AI
Overviewina stable`aria-label`/`role`container. Strategy1(worksinany
language):find the card by its jscontroller. Strategy2(fallback):anchoron the visible heading text,then climb to the card by walking up whiletheset of external citation domains stays the same — stopping before the climbreaches the organic results(`#rso`/`#search`)or a neighbouring feature."""
el = _aio_controller_el(soup)ifel is not None and _external_citation_urls(el):returnelheading = NoneformarkerinAI_OVERVIEW_MARKERS:node = soup.find(string=lambda s:s is not None and s.strip() == marker)ifnode is not None:heading = node.parentbreakifheading is None:returnNoneblock,cur,plateau = heading,heading,Nonefor_inrange(20):cur = cur.parentifcur is None or cur.select_one("#rso")or cur.select_one("#search"):breakurls = _external_citation_urls(cur)ifnot urls:block = curelif plateau is None or urls == plateau:plateau,block = urls,curelse:breakreturnblockdef _organic_from_soup(soup,aio_block,*,start_rank:int):
# Scope to the main results column;fall back to the whole doc ifneeded.
container = soup.select_one("#rso")or soup.select_one("#search")or soup
results:list[OrganicResult] = []
seen:set[str] = set()rank = start_rankforh3incontainer.select("a h3"):anchor = h3.find_parent("a")ifnot anchor or not anchor.get("href"):continue
# Exclude AI-Overview citation links by DOM containment,not by URL:a
# page can be both AIO-cited and organically ranked,and the organic
# result must still count.
ifaio_block is not None and aio_blockinanchor.parents:continueurl = _clean_google_url(str(anchor["href"]))ifnot url:continuedomain = _domain_of(url)ifnot domain or "google."indomain or urlinseen:continueseen.add(url)results.append(OrganicResult(rank,h3.get_text(strip=True),url,domain))rank += 1returnresultsdef parse_serp(html: str,*,start_rank:int = 1) -> SerpResult:"""Parse one rendered SERP page into organic results, AI-Overview presence,
and the domains it cites. `start_rank` offsets positions when paginating."""
soup = BeautifulSoup(html, "lxml")
block = _aio_block(soup)
aio_urls = _external_citation_urls(block) if block is not None else set()
aio_domains = sorted({d for d in (_domain_of(u) for u in aio_urls) if d})
return SerpResult(
organic=_organic_from_soup(soup, block, start_rank=start_rank),
ai_overview=_has_ai_overview(soup),
ai_overview_domains=aio_domains,
)
def find_rank(results: list[OrganicResult], target_domain: str):
"""First organic result matching target_domain (or a subdomain), or None."""
target = _norm_target(target_domain)
for r in results:
if r.domain == target or r.domain.endswith("." + target):
return r
return None
def domain_cited(domains: list[str], target_domain: str) -> bool:
"""True if target_domain (or a subdomain) is cited in the AI Overview."""
target = _norm_target(target_domain)
return any(d == target or d.endswith("." + target) for d in domains)
parse_serp() walks the HTML (often 1 MB+) once and returns three values: organic results, AI-Overview presence, and the domains cited inside the AI Overview. It uses a h3 inside #rso / #search as the anchor. This title-link structure has held up across many years of Google redesigns; CSS class names like .g or .yuRUbf change often. The citation links physically inside the AI Overview block are excluded from the organic count and returned as ai_overview_domains. This exclusion is by DOM position, not by URL: a page that genuinely ranks organically still counts at its real position even when Google also cites the same page in the AI Overview (the two are independent signals, and both are reported). find_rank and domain_cited both accept subdomains, so blog.hypeproxies.com matches hypeproxies.com.
> When Google changes its HTML (and it will), the fix is in this one file; it does not require changes in network or runner code.
Clean before counting
For a rank tracker, the position number is the output. Invalid links (tracking parameters, duplicate sitelinks, empty titles, AI-Overview citations) silently increase the count. The repo's cleaning layer normalizes and validates every parsed link before counting it. This is the difference between reporting rank 2 and reporting a wrong rank 4.
What counts as rank 1?
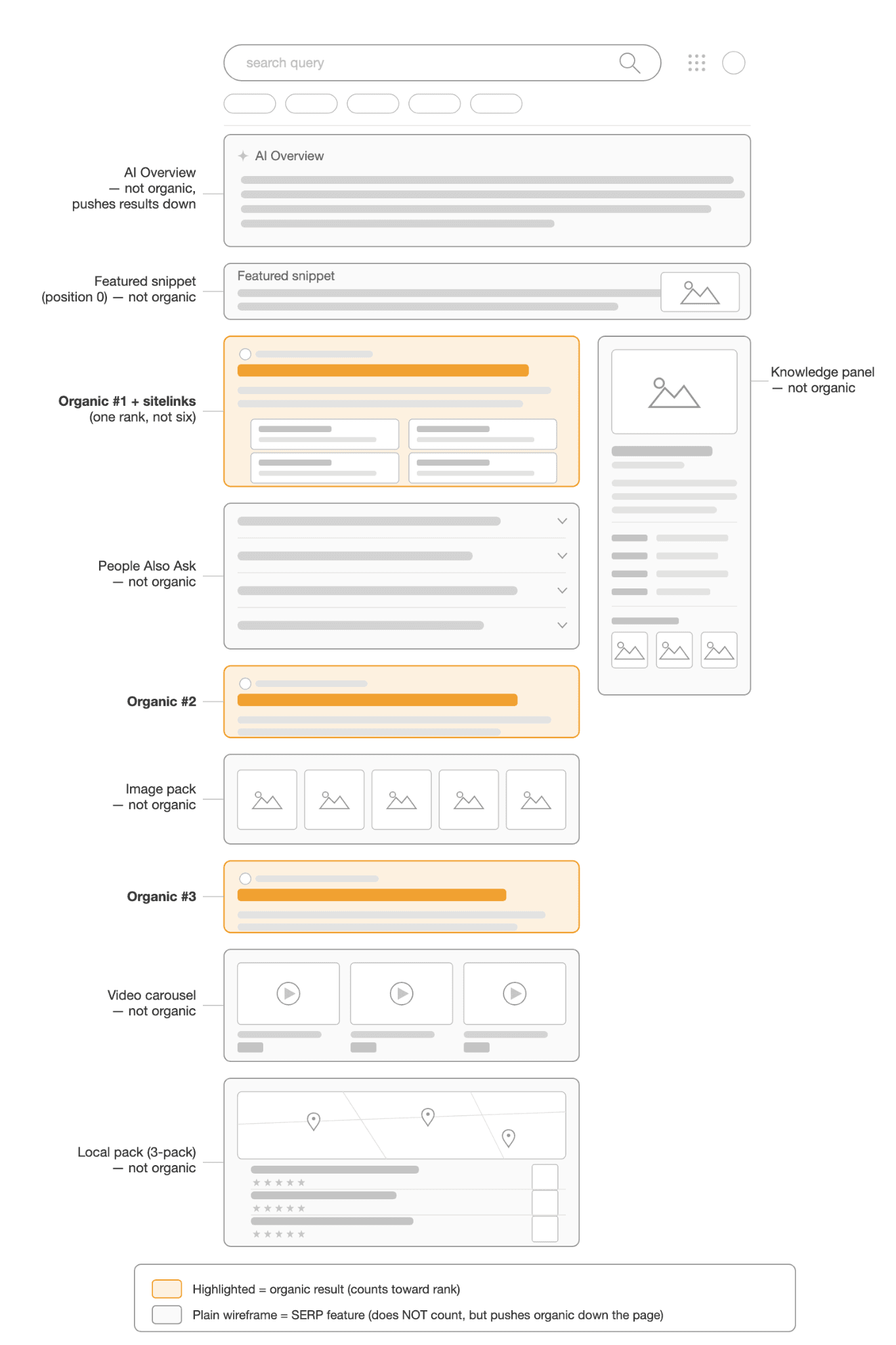
Google's SERP has many feature types that complicate the simple notion of position. Pick a methodology and apply it consistently, or different runs will silently measure different things:
Featured snippet. The answer box at the top, sometimes called "position 0", must not count as a rank number. Our parser handles this automatically, because the answer box sits outside #rso and carries no a h3 title link, so it never enters the organic count. If you want to record its presence, add a field the same way ai_overview is tracked. Google removed the visible "Featured snippet" label years ago and increasingly replaces these boxes with AI Overviews, so detecting the box reliably is harder than detecting the AI Overview.
Sitelinks. The 4–6 indented sub-links under one result count as one rank, not six.
"People Also Ask" boxes. Skip these entirely. They are not organic, but they push the organic results down the page.
Image packs, video carousels, knowledge panels, local pack. None of these are organic. They use space on the page but do not count toward the rank. Track them in separate fields if you need this data.
AI Overview. This is already handled above. The parser excludes it from organic results and tracks it separately as ai_overview and ai_cited.
A commercial-query SERP, drawn as a wireframe with the common features stacked together. Only the highlighted organic results count toward rank – everything else (AI Overview, featured snippet, People Also Ask, image pack, video carousel, local pack, knowledge panel) is a SERP feature that pushes organic results further down the page. Sitelinks under organic #1 are part of that result, not six separate ranks.
Our parser uses the strict definition: organic = an a h3 result inside #rso / #search, after AI-Overview links are removed and Google's own properties are excluded. Featured snippets and the others are separate signals; they do not increase the rank count. Choose your methodology, document it, and do not change it later without notice, because otherwise your trends between weeks are not comparable.
AI Overview tracking
By 2026, AI Overviews (Google's generative summary box, formerly SGE) sit above every organic result on a large share of commercial SERPs. They render asynchronously via JavaScript and can take seconds to appear after the rest of the page loads. The same query may return an AIO in one request and no AIO in the next.
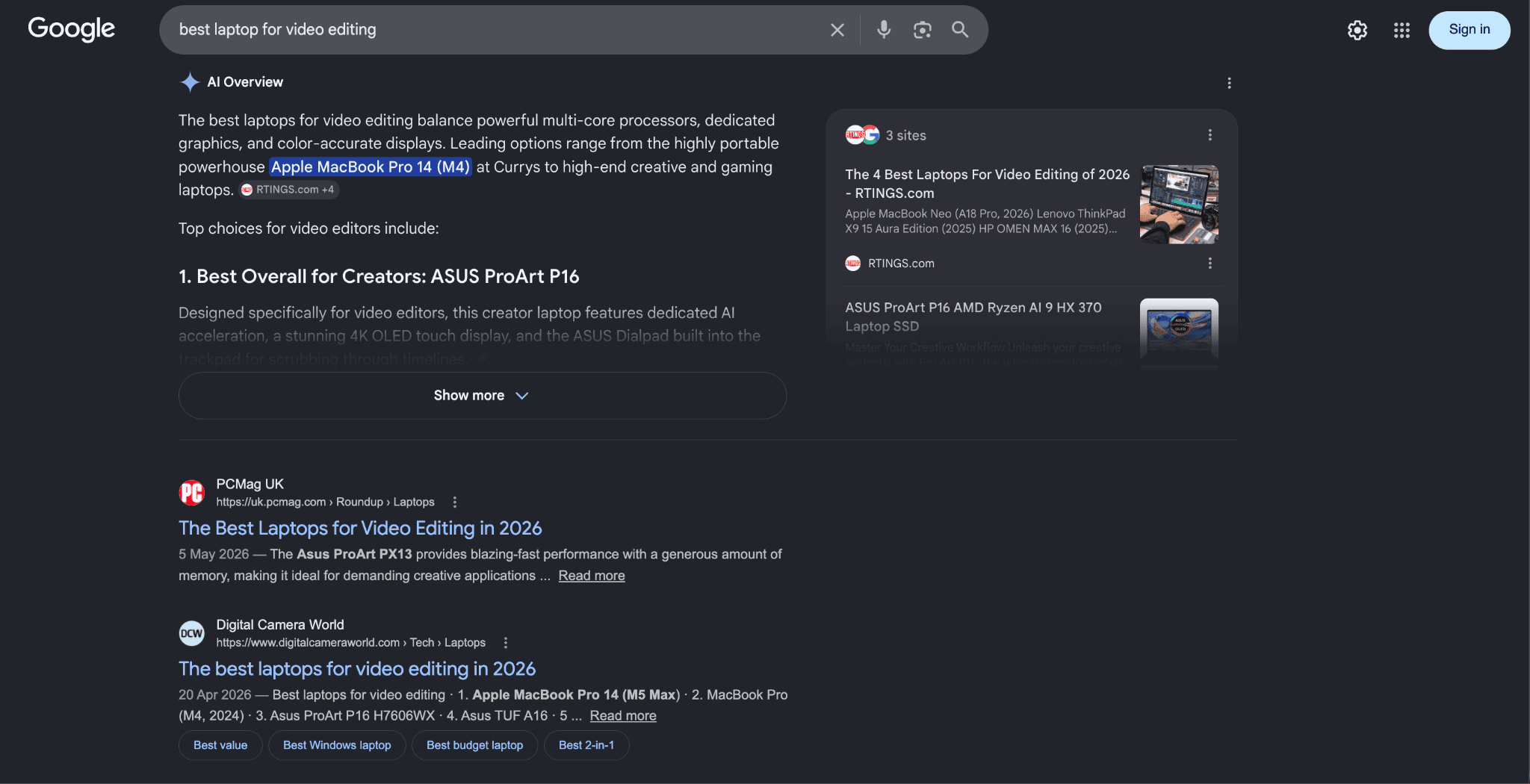
A real SERP showing the displacement in practice: the AI Overview consumes the entire above-the-fold area, and the first organic result (PCMag UK) only appears at the bottom of the visible page. The "Show more" button means the AIO is even bigger than what's shown. This is what "AI Overviews sit above every organic result" looks like on a real query – they don't share space with organic results; they push them down the page.
Two problems for rank tracking
For a rank tracker, AI Overviews create two problems you must handle deliberately:
They distort "position 1". A user now scrolls past the AI Overview before reaching organic result #1. If your tracker silently counts links inside the AI Overview as organic, your positions are wrong. Our parser collects AI Overview URLs and excludes them, so rank #1 means the first organic result beneath the AI Overview.
Being cited in the AI Overview is becoming the new "position 1". Whether your keyword triggers an AI Overview, and especially whether your domain is cited inside it, increasingly matters as much as the classic organic rank. In 2026, a brand can be "rank 6 organically but cited in the AI Overview", which may be the more valuable placement. So we track both. We've broken down why this citation shift is redefining rank tracking itself across Google and the answer engines.
Detecting both with one parse
The same code that excludes AI Overview links from your organic count also tells you which domains are cited inside the AI Overview:
from parser importparse_serp,find_rank,domain_citedserp = parse_serp(rendered_html) # returns SerpResult:organic + ai_overview + ai_overview_domainsrank = find_rank(serp.organic,"yourdomain.com")print("AI Overview present:",serp.ai_overview)print("Cited in the AI Overview:",domain_cited(serp.ai_overview_domains,"yourdomain.com"))print("Organic rank:",rank.positionifrank else"not in range")
from parser importparse_serp,find_rank,domain_citedserp = parse_serp(rendered_html) # returns SerpResult:organic + ai_overview + ai_overview_domainsrank = find_rank(serp.organic,"yourdomain.com")print("AI Overview present:",serp.ai_overview)print("Cited in the AI Overview:",domain_cited(serp.ai_overview_domains,"yourdomain.com"))print("Organic rank:",rank.positionifrank else"not in range")
from parser importparse_serp,find_rank,domain_citedserp = parse_serp(rendered_html) # returns SerpResult:organic + ai_overview + ai_overview_domainsrank = find_rank(serp.organic,"yourdomain.com")print("AI Overview present:",serp.ai_overview)print("Cited in the AI Overview:",domain_cited(serp.ai_overview_domains,"yourdomain.com"))print("Organic rank:",rank.positionifrank else"not in range")
The tracker stores all of it, and the console output prints [AI Overview: CITED] when your domain is cited inside the AI Overview. Citation tracking like this is still uncommon in off-the-shelf tools.
Reading the detection signal
Google's AI-Overview HTML varies by query and by region, and Google changes it without notice. The tracker treats that as a design constraint, not a surprise: detection is built as a high-confidence signal rather than a guarantee, and it is isolated in one function, so when the markup changes you update one place and your history stays intact.
The detection uses two independent signals, so it survives more than one kind of change. The first is the visible heading text ("AI Overview" in English, "Übersicht mit KI" in German), which is language-specific. The second is the AI-Overview card's jscontroller, which was the same across the locales we checked, so it is more likely to keep working when you track a locale whose heading text is not in the list. We verified detection for English and German; for any other UI language the tracker prints a warning at startup, so an AI Overview it cannot yet recognize shows up as a logged warning instead of a silent zero. When that happens, you add the new language's heading text (and, if Google has rotated it, the new jscontroller) to one short list.
AI Overviews also flicker. The same query, sent twice 5 minutes apart, can return an AIO in one response and no AIO in the next. One check without an AIO does not mean the AIO is gone for that keyword; it means the AIO did not render in this check. AIO presence for a query is closer to a probability than a binary fact. A tracker that alerts on a single run will produce false "lost AIO citation" alerts quickly. This one does not, because it stores every check, which turns the right metric into a rolling window: "AIO appeared in 5 of the last 7 daily checks for "isp proxies"" is a query on the history table, not extra scraping.
Storage
With detection wired in, every result lands in SQLite (position, AI-Overview presence, and whether the target was cited), so movement is chartable across weeks and months.
storage.py:
"""SQLite storage for rank snapshots."""from __future__ importannotationsimportsqlite3fromcontextlib import contextmanager
from datetime importdatetime,timezonefrompathlib import Path
SCHEMA = """
CREATE TABLE IF NOT EXISTS rank_checks(id INTEGER PRIMARY KEY AUTOINCREMENT,checked_at TEXT NOT NULL,keyword TEXT NOT NULL,location TEXT NOT NULL,target_domain TEXT NOT NULL,position INTEGER, -- NULL = not foundinrangeranked_url TEXT,found INTEGER NOT NULL, -- 1/0ai_overview INTEGER NOT NULL DEFAULT 0, -- 1 = AI Overview shown forqueryai_cited INTEGER NOT NULL DEFAULT 0 -- 1 = target cited inside the AIO);CREATE INDEX IF NOT EXISTS idx_lookupON rank_checks(keyword,location,checked_at);"""
class Storage:
def __init__(self,db_path:str = "rankings.db"):self.db_path = str(Path(db_path))withself._conn()as c:c.executescript(SCHEMA)
@contextmanagerdef _conn(self):conn = sqlite3.connect(self.db_path)conn.row_factory = sqlite3.Rowtry:yieldconnconn.commit()finally:conn.close()def save(self, *,keyword:str,location:str,target_domain:str,position:int | None,ranked_url:str | None,ai_overview:bool = False,ai_cited:bool = False) -> None:withself._conn()as c:c.execute("""INSERT INTO rank_checks
(checked_at,keyword,location,target_domain,position,ranked_url,found,ai_overview,ai_cited)VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?)""",(datetime.now(timezone.utc).isoformat(timespec="seconds"),keyword,location,target_domain,position,ranked_url,1if position is not None else 0,1if ai_overview else 0,1if ai_cited else 0),)def history(self,keyword: str,location: str,limit: int = 30):withself._conn()as c:rows = c.execute("""SELECT checked_at, position FROM rank_checks
WHERE keyword = ? AND location = ?
ORDER BYchecked_at DESC LIMIT ?""",
(keyword,location,limit),).fetchall()return[dict(r)for r inrows]
"""SQLite storage for rank snapshots."""from __future__ importannotationsimportsqlite3fromcontextlib import contextmanager
from datetime importdatetime,timezonefrompathlib import Path
SCHEMA = """
CREATE TABLE IF NOT EXISTS rank_checks(id INTEGER PRIMARY KEY AUTOINCREMENT,checked_at TEXT NOT NULL,keyword TEXT NOT NULL,location TEXT NOT NULL,target_domain TEXT NOT NULL,position INTEGER, -- NULL = not foundinrangeranked_url TEXT,found INTEGER NOT NULL, -- 1/0ai_overview INTEGER NOT NULL DEFAULT 0, -- 1 = AI Overview shown forqueryai_cited INTEGER NOT NULL DEFAULT 0 -- 1 = target cited inside the AIO);CREATE INDEX IF NOT EXISTS idx_lookupON rank_checks(keyword,location,checked_at);"""
class Storage:
def __init__(self,db_path:str = "rankings.db"):self.db_path = str(Path(db_path))withself._conn()as c:c.executescript(SCHEMA)
@contextmanagerdef _conn(self):conn = sqlite3.connect(self.db_path)conn.row_factory = sqlite3.Rowtry:yieldconnconn.commit()finally:conn.close()def save(self, *,keyword:str,location:str,target_domain:str,position:int | None,ranked_url:str | None,ai_overview:bool = False,ai_cited:bool = False) -> None:withself._conn()as c:c.execute("""INSERT INTO rank_checks
(checked_at,keyword,location,target_domain,position,ranked_url,found,ai_overview,ai_cited)VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?)""",(datetime.now(timezone.utc).isoformat(timespec="seconds"),keyword,location,target_domain,position,ranked_url,1if position is not None else 0,1if ai_overview else 0,1if ai_cited else 0),)def history(self,keyword: str,location: str,limit: int = 30):withself._conn()as c:rows = c.execute("""SELECT checked_at, position FROM rank_checks
WHERE keyword = ? AND location = ?
ORDER BYchecked_at DESC LIMIT ?""",
(keyword,location,limit),).fetchall()return[dict(r)for r inrows]
"""SQLite storage for rank snapshots."""from __future__ importannotationsimportsqlite3fromcontextlib import contextmanager
from datetime importdatetime,timezonefrompathlib import Path
SCHEMA = """
CREATE TABLE IF NOT EXISTS rank_checks(id INTEGER PRIMARY KEY AUTOINCREMENT,checked_at TEXT NOT NULL,keyword TEXT NOT NULL,location TEXT NOT NULL,target_domain TEXT NOT NULL,position INTEGER, -- NULL = not foundinrangeranked_url TEXT,found INTEGER NOT NULL, -- 1/0ai_overview INTEGER NOT NULL DEFAULT 0, -- 1 = AI Overview shown forqueryai_cited INTEGER NOT NULL DEFAULT 0 -- 1 = target cited inside the AIO);CREATE INDEX IF NOT EXISTS idx_lookupON rank_checks(keyword,location,checked_at);"""
class Storage:
def __init__(self,db_path:str = "rankings.db"):self.db_path = str(Path(db_path))withself._conn()as c:c.executescript(SCHEMA)
@contextmanagerdef _conn(self):conn = sqlite3.connect(self.db_path)conn.row_factory = sqlite3.Rowtry:yieldconnconn.commit()finally:conn.close()def save(self, *,keyword:str,location:str,target_domain:str,position:int | None,ranked_url:str | None,ai_overview:bool = False,ai_cited:bool = False) -> None:withself._conn()as c:c.execute("""INSERT INTO rank_checks
(checked_at,keyword,location,target_domain,position,ranked_url,found,ai_overview,ai_cited)VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?)""",(datetime.now(timezone.utc).isoformat(timespec="seconds"),keyword,location,target_domain,position,ranked_url,1if position is not None else 0,1if ai_overview else 0,1if ai_cited else 0),)def history(self,keyword: str,location: str,limit: int = 30):withself._conn()as c:rows = c.execute("""SELECT checked_at, position FROM rank_checks
WHERE keyword = ? AND location = ?
ORDER BYchecked_at DESC LIMIT ?""",
(keyword,location,limit),).fetchall()return[dict(r)for r inrows]
No extra dependencies, and suitable for millions of rows. If your data grows beyond SQLite, the schema and access patterns port to Postgres with minor changes (you swap the connection layer and adjust a little SQL).
Tracker loop
The tracker loop ties the modules together. For each keyword × location it paginates through the SERP with start= until it finds the target or reaches max_depth. It records whether an AI Overview is present (and whether the target domain is cited in it), then stores the result. It throttles between requests. Each fetch_page call starts a new anti-detect browser on a fresh proxy. The repo's sticky-session version reuses one browser across a keyword's pages.
tracker.py:
"""Orchestrator — runs rank checks for every keyword and location."""from __future__ importannotationsimportargparseimportrandomimporttimefromdataclasses importreplaceimportyamlfromfetcher importSerpFetcher,BlockedError,FetchErrorfromparser import parse_serp, find_rank, domain_cited
from proxy_pool importProxyPoolfromstorage import Storage
RESULTS_PER_PAGE = 10def check_keyword(fetcher,keyword,target_domain, *,gl,hl,max_depth):"""Page through the SERP until the target is found or depth is reached.
Returns(position,ranked_url,ai_overview,ai_cited)."""
pages = max(1,max_depth // RESULTS_PER_PAGE)ai_overview = ai_cited = False
# Number positions continuously by KEPT organic results,and de-duplicate
# across pages. Not`start + 1`:ifa page returns fewer than 10kept results
# (a filteredGoogle property,a dupe),`start + 1`leaves a gap at the page
# boundary and shifts every later rank.
next_rank = 1seen_urls = set()forpageinrange(pages):start = page * RESULTS_PER_PAGEhtml = fetcher.fetch_page(keyword,start=start,gl=gl,hl=hl)serp = parse_serp(html)ifpage == 0:ai_overview = serp.ai_overviewai_cited = domain_cited(serp.ai_overview_domains,target_domain)page_results = []foroinserp.organic:ifo.urlinseen_urls:continueseen_urls.add(o.url)page_results.append(replace(o,position=next_rank))next_rank += 1hit = find_rank(page_results,target_domain)if hit:returnhit.position,hit.url,ai_overview,ai_citedifnot serp.organic:breaktime.sleep(random.uniform(1.5,4.0)) # throttle between pagesreturnNone,None,ai_overview,ai_citeddef run(config_path="keywords.yaml",proxies_path="proxies.txt",db_path="rankings.db"):cfg = yaml.safe_load(open(config_path))target = cfg["target_domain"]max_depth = cfg.get("max_depth",20)pool = ProxyPool.from_file(proxies_path)store = Storage(db_path)print(f"Tracking {len(cfg['keywords'])} keyword(s) for {target}")print(f"Proxypool:{pool.stats()}\n")
withSerpFetcher(pool)as fetcher:forkeywordincfg["keywords"]:forlocincfg["locations"]:label = loc["label"]try:pos,url,aio,cited = check_keyword(fetcher,keyword,target,gl=loc["gl"],hl=loc["hl"],max_depth=max_depth,)except(BlockedError,FetchError)as exc:print(f"x [{label}]{keyword!r}:failed({exc})")
continuestore.save(keyword=keyword,location=label,target_domain=target,position=pos,ranked_url=url,ai_overview=aio,ai_cited=cited)
# Mark whether the target domain is cited inside the AI Overview.
tag = (" [AI Overview: CITED]"ifcitedelse" [AI Overview]"ifaio else"")if pos:print(f" + [{label}]{keyword!r}:position {pos}{tag}")
else:print(f" - [{label}]{keyword!r}:"
f"not in top {max_depth}{tag}")time.sleep(random.uniform(3.0,7.0)) # throttle between queriesprint(f"\nDone. Final pool state: {pool.stats()}")if__name__ == "__main__":ap = argparse.ArgumentParser(description="SEO rank tracker")ap.add_argument("--config",default="keywords.yaml")ap.add_argument("--proxies",default="proxies.txt")ap.add_argument("--db",default="rankings.db")args = ap.parse_args()run(args.config,args.proxies,args.db)
"""Orchestrator — runs rank checks for every keyword and location."""from __future__ importannotationsimportargparseimportrandomimporttimefromdataclasses importreplaceimportyamlfromfetcher importSerpFetcher,BlockedError,FetchErrorfromparser import parse_serp, find_rank, domain_cited
from proxy_pool importProxyPoolfromstorage import Storage
RESULTS_PER_PAGE = 10def check_keyword(fetcher,keyword,target_domain, *,gl,hl,max_depth):"""Page through the SERP until the target is found or depth is reached.
Returns(position,ranked_url,ai_overview,ai_cited)."""
pages = max(1,max_depth // RESULTS_PER_PAGE)ai_overview = ai_cited = False
# Number positions continuously by KEPT organic results,and de-duplicate
# across pages. Not`start + 1`:ifa page returns fewer than 10kept results
# (a filteredGoogle property,a dupe),`start + 1`leaves a gap at the page
# boundary and shifts every later rank.
next_rank = 1seen_urls = set()forpageinrange(pages):start = page * RESULTS_PER_PAGEhtml = fetcher.fetch_page(keyword,start=start,gl=gl,hl=hl)serp = parse_serp(html)ifpage == 0:ai_overview = serp.ai_overviewai_cited = domain_cited(serp.ai_overview_domains,target_domain)page_results = []foroinserp.organic:ifo.urlinseen_urls:continueseen_urls.add(o.url)page_results.append(replace(o,position=next_rank))next_rank += 1hit = find_rank(page_results,target_domain)if hit:returnhit.position,hit.url,ai_overview,ai_citedifnot serp.organic:breaktime.sleep(random.uniform(1.5,4.0)) # throttle between pagesreturnNone,None,ai_overview,ai_citeddef run(config_path="keywords.yaml",proxies_path="proxies.txt",db_path="rankings.db"):cfg = yaml.safe_load(open(config_path))target = cfg["target_domain"]max_depth = cfg.get("max_depth",20)pool = ProxyPool.from_file(proxies_path)store = Storage(db_path)print(f"Tracking {len(cfg['keywords'])} keyword(s) for {target}")print(f"Proxypool:{pool.stats()}\n")
withSerpFetcher(pool)as fetcher:forkeywordincfg["keywords"]:forlocincfg["locations"]:label = loc["label"]try:pos,url,aio,cited = check_keyword(fetcher,keyword,target,gl=loc["gl"],hl=loc["hl"],max_depth=max_depth,)except(BlockedError,FetchError)as exc:print(f"x [{label}]{keyword!r}:failed({exc})")
continuestore.save(keyword=keyword,location=label,target_domain=target,position=pos,ranked_url=url,ai_overview=aio,ai_cited=cited)
# Mark whether the target domain is cited inside the AI Overview.
tag = (" [AI Overview: CITED]"ifcitedelse" [AI Overview]"ifaio else"")if pos:print(f" + [{label}]{keyword!r}:position {pos}{tag}")
else:print(f" - [{label}]{keyword!r}:"
f"not in top {max_depth}{tag}")time.sleep(random.uniform(3.0,7.0)) # throttle between queriesprint(f"\nDone. Final pool state: {pool.stats()}")if__name__ == "__main__":ap = argparse.ArgumentParser(description="SEO rank tracker")ap.add_argument("--config",default="keywords.yaml")ap.add_argument("--proxies",default="proxies.txt")ap.add_argument("--db",default="rankings.db")args = ap.parse_args()run(args.config,args.proxies,args.db)
"""Orchestrator — runs rank checks for every keyword and location."""from __future__ importannotationsimportargparseimportrandomimporttimefromdataclasses importreplaceimportyamlfromfetcher importSerpFetcher,BlockedError,FetchErrorfromparser import parse_serp, find_rank, domain_cited
from proxy_pool importProxyPoolfromstorage import Storage
RESULTS_PER_PAGE = 10def check_keyword(fetcher,keyword,target_domain, *,gl,hl,max_depth):"""Page through the SERP until the target is found or depth is reached.
Returns(position,ranked_url,ai_overview,ai_cited)."""
pages = max(1,max_depth // RESULTS_PER_PAGE)ai_overview = ai_cited = False
# Number positions continuously by KEPT organic results,and de-duplicate
# across pages. Not`start + 1`:ifa page returns fewer than 10kept results
# (a filteredGoogle property,a dupe),`start + 1`leaves a gap at the page
# boundary and shifts every later rank.
next_rank = 1seen_urls = set()forpageinrange(pages):start = page * RESULTS_PER_PAGEhtml = fetcher.fetch_page(keyword,start=start,gl=gl,hl=hl)serp = parse_serp(html)ifpage == 0:ai_overview = serp.ai_overviewai_cited = domain_cited(serp.ai_overview_domains,target_domain)page_results = []foroinserp.organic:ifo.urlinseen_urls:continueseen_urls.add(o.url)page_results.append(replace(o,position=next_rank))next_rank += 1hit = find_rank(page_results,target_domain)if hit:returnhit.position,hit.url,ai_overview,ai_citedifnot serp.organic:breaktime.sleep(random.uniform(1.5,4.0)) # throttle between pagesreturnNone,None,ai_overview,ai_citeddef run(config_path="keywords.yaml",proxies_path="proxies.txt",db_path="rankings.db"):cfg = yaml.safe_load(open(config_path))target = cfg["target_domain"]max_depth = cfg.get("max_depth",20)pool = ProxyPool.from_file(proxies_path)store = Storage(db_path)print(f"Tracking {len(cfg['keywords'])} keyword(s) for {target}")print(f"Proxypool:{pool.stats()}\n")
withSerpFetcher(pool)as fetcher:forkeywordincfg["keywords"]:forlocincfg["locations"]:label = loc["label"]try:pos,url,aio,cited = check_keyword(fetcher,keyword,target,gl=loc["gl"],hl=loc["hl"],max_depth=max_depth,)except(BlockedError,FetchError)as exc:print(f"x [{label}]{keyword!r}:failed({exc})")
continuestore.save(keyword=keyword,location=label,target_domain=target,position=pos,ranked_url=url,ai_overview=aio,ai_cited=cited)
# Mark whether the target domain is cited inside the AI Overview.
tag = (" [AI Overview: CITED]"ifcitedelse" [AI Overview]"ifaio else"")if pos:print(f" + [{label}]{keyword!r}:position {pos}{tag}")
else:print(f" - [{label}]{keyword!r}:"
f"not in top {max_depth}{tag}")time.sleep(random.uniform(3.0,7.0)) # throttle between queriesprint(f"\nDone. Final pool state: {pool.stats()}")if__name__ == "__main__":ap = argparse.ArgumentParser(description="SEO rank tracker")ap.add_argument("--config",default="keywords.yaml")ap.add_argument("--proxies",default="proxies.txt")ap.add_argument("--db",default="rankings.db")args = ap.parse_args()run(args.config,args.proxies,args.db)
That x ... failed line is intentional: the tracker reports the failure instead of inventing a rank value. The basic version logs it, benches the IP, and continues.
The random throttling between requests (time.sleep(random.uniform(...))) is important. Human-like, irregular timing is one of the most effective anti-detection measures, much better than a tight uniform loop. Once you have the right engine (camoufox over Chromium), most remaining blocks are avoided by good pacing and a diverse pool rather than by further clever tricks.
The repo's version goes further in four ways that are useful in production.
Triage why a check failed
The failure to watch for is the silent one. If the SERP loads but the parser returns 0 organic results, this is almost always a parse failure (Google changed the HTML), not a real ranking loss. The repo marks parse_failure separately, writes a debug bundle (the raw SERP plus a parser-fix prompt for an LLM or developer), and adds it to an incident timeline. A MAINTENANCE.md runbook describes the fix steps for a developer or AI agent, and the fixed SERP is added to fixtures/ as a regression test so the same break is caught next time.
Grade the run
A run with most checks blocked should not be reported as success. The repo computes a health verdict (healthy / degraded / failed) from the share of checks that produced usable data, and the CLI exits with a non-zero code so cron and monitoring can detect a failed run.
Alert on movement
Rank tracking is a form of change monitoring. After each run the repo compares results to the previous snapshot and sends alerts for meaningful changes (entered or left the top N, gained or lost a ranking, large jumps), with an optional --webhook to Slack, Discord, or any webhook endpoint.
Filter the noise
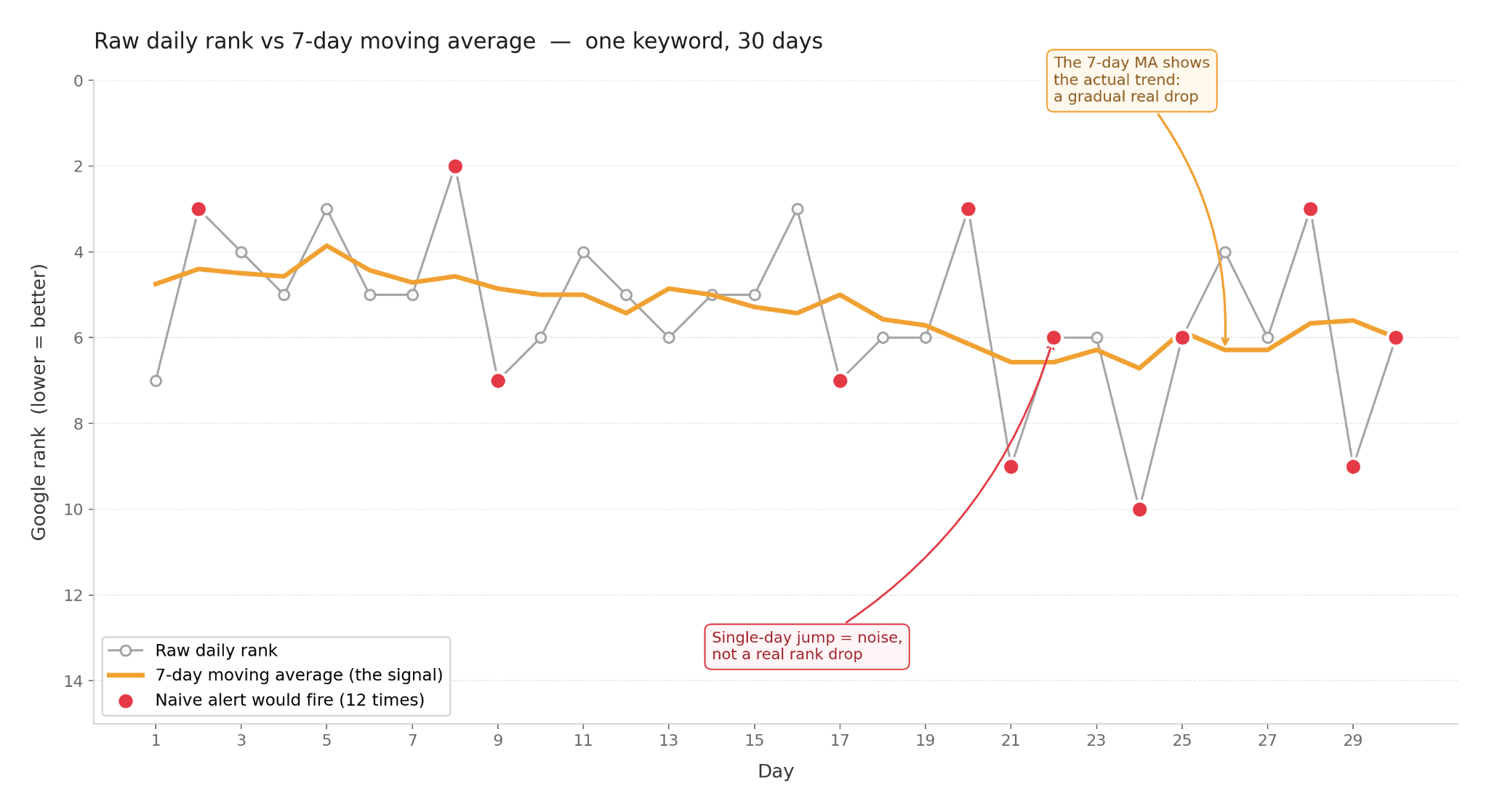
A keyword going 5 → 7 → 5 → 6 over four days is noise, not a real change. Alerting on every position change fills the channel fast, and you will mute it. The rules that work in production: require N consecutive moves in the same direction before alerting (typically 2 or 3), use volatility-aware thresholds (some keywords change ±3 positions daily as their baseline), and use a 7-day moving average for trend detection. Single-day deltas are useful for manual checks, not for automated alerts.
Same keyword, same 30 days, two readings. The raw daily line (gray) triggers a naive alert 12 times – that's a Slack channel you'll mute fast. The 7-day moving average (amber) is the actual signal: a slow drift from rank 5 to rank 6 over the month.
The teaching tracker.py above takes just --config, --proxies, and --db. The fuller version in the repo adds the production flags and helper scripts below (build these on top of the loop you already have, or clone the repo):
python tracker.py --smoke #test one keyword before the full runpython tracker.py --json #machine-readable output(progress tostderr)python tracker.py --respect-robots #abort ifrobots.txtdisallows /searchpython tracker.py --webhook <url> # POST rank-change alertspython test_parser.py # golden-fixture parser regression gatepython incidents.py # the "what broke and when"timeline
python tracker.py --smoke #test one keyword before the full runpython tracker.py --json #machine-readable output(progress tostderr)python tracker.py --respect-robots #abort ifrobots.txtdisallows /searchpython tracker.py --webhook <url> # POST rank-change alertspython test_parser.py # golden-fixture parser regression gatepython incidents.py # the "what broke and when"timeline
python tracker.py --smoke #test one keyword before the full runpython tracker.py --json #machine-readable output(progress tostderr)python tracker.py --respect-robots #abort ifrobots.txtdisallows /searchpython tracker.py --webhook <url> # POST rank-change alertspython test_parser.py # golden-fixture parser regression gatepython incidents.py # the "what broke and when"timeline
Scheduler
A daily check is usually enough. System cron works; APScheduler is self-contained and cross-platform.
schedule_runner.py:
"""Run the tracker on a daily schedule."""from apscheduler.schedulers.blockingimportBlockingSchedulerfromtracker importrunscheduler = BlockingScheduler(timezone="UTC")
@scheduler.scheduled_job("cron",hour=6,minute=0)def daily_job():print("=== Daily rank check starting ===")run()if__name__ == "__main__":print("Scheduler started. Daily run at 06:00 UTC. Ctrl-C to exit.")try:scheduler.start()except(KeyboardInterrupt,SystemExit):print("\nScheduler stopped.")
"""Run the tracker on a daily schedule."""from apscheduler.schedulers.blockingimportBlockingSchedulerfromtracker importrunscheduler = BlockingScheduler(timezone="UTC")
@scheduler.scheduled_job("cron",hour=6,minute=0)def daily_job():print("=== Daily rank check starting ===")run()if__name__ == "__main__":print("Scheduler started. Daily run at 06:00 UTC. Ctrl-C to exit.")try:scheduler.start()except(KeyboardInterrupt,SystemExit):print("\nScheduler stopped.")
"""Run the tracker on a daily schedule."""from apscheduler.schedulers.blockingimportBlockingSchedulerfromtracker importrunscheduler = BlockingScheduler(timezone="UTC")
@scheduler.scheduled_job("cron",hour=6,minute=0)def daily_job():print("=== Daily rank check starting ===")run()if__name__ == "__main__":print("Scheduler started. Daily run at 06:00 UTC. Ctrl-C to exit.")try:scheduler.start()except(KeyboardInterrupt,SystemExit):print("\nScheduler stopped.")
Run it using:
Run it using:
Run it using:
Run it using:
If you would rather use system cron, the one-liner is:
# Run every day at 06:0006 * * * cd /path/to/rank-tracker && ./venv/bin/python tracker.py >> tracker.log2>&1
# Run every day at 06:0006 * * * cd /path/to/rank-tracker && ./venv/bin/python tracker.py >> tracker.log2>&1
# Run every day at 06:0006 * * * cd /path/to/rank-tracker && ./venv/bin/python tracker.py >> tracker.log2>&1
Either way, the tracker needs a machine that is always on. A small VPS is enough for a few hundred keywords; the camoufox renders are the heavy part, and they run one at a time in the basic loop.
For heavier workloads, spread checks across the day instead of running everything at 6 AM. This distributes proxy load and looks more like normal user behavior. APScheduler supports this with multiple jobs or a jittered interval trigger.
Reporting
With scheduled runs accumulating in the database, you need a way to look at them. This script prints the latest position and the change since the previous check.
report.py:
"""Console report: current rank and movement per keyword/location."""from __future__ importannotationsimportyamlfromtabulate import tabulate
from storage importStoragedef movement_symbol(curr,prev):ifcurr is None and prev is None:return"—" # never ranked yet(e.g. a fresh database)ifcurr is None:return"lost" # was ranked,now goneifprev is None:return"new"if curr <prev:returnf"up +{prev - curr}"ifcurr> prev:
return f"down -{curr - prev}
"""Console report: current rank and movement per keyword/location."""from __future__ importannotationsimportyamlfromtabulate import tabulate
from storage importStoragedef movement_symbol(curr,prev):ifcurr is None and prev is None:return"—" # never ranked yet(e.g. a fresh database)ifcurr is None:return"lost" # was ranked,now goneifprev is None:return"new"if curr <prev:returnf"up +{prev - curr}"ifcurr> prev:
return f"down -{curr - prev}
"""Console report: current rank and movement per keyword/location."""from __future__ importannotationsimportyamlfromtabulate import tabulate
from storage importStoragedef movement_symbol(curr,prev):ifcurr is None and prev is None:return"—" # never ranked yet(e.g. a fresh database)ifcurr is None:return"lost" # was ranked,now goneifprev is None:return"new"if curr <prev:returnf"up +{prev - curr}"ifcurr> prev:
return f"down -{curr - prev}
The Change column shows useful data from the second run onward, once a previous snapshot exists for comparison (on the first run, every ranked keyword shows new):
| Keyword | Location | Rank | Change |
|---------------------------|----------|------|---------|
| isp proxies | US | 4 | up +2 |
| isp proxies | UK | 6 | = 0 |
| isp proxies | DE | — | lost |
| static residential proxy | UK | 9 | down -1
| Keyword | Location | Rank | Change |
|---------------------------|----------|------|---------|
| isp proxies | US | 4 | up +2 |
| isp proxies | UK | 6 | = 0 |
| isp proxies | DE | — | lost |
| static residential proxy | UK | 9 | down -1
| Keyword | Location | Rank | Change |
|---------------------------|----------|------|---------|
| isp proxies | US | 4 | up +2 |
| isp proxies | UK | 6 | = 0 |
| isp proxies | DE | — | lost |
| static residential proxy | UK | 9 | down -1
Next steps: a dashboard such as Grafana, a weekly email digest, or CSV export. The data is already in SQLite. The ai_overview and ai_cited columns let you chart AI-Overview rollout (and your own citations) against classic rankings.
Proxy best practices
A clean ISP pool does most of the work; how you use it decides whether it stays effective. The habits that matter:
Pace with human-like timing. A 3–7 second jitter between queries is a reasonable minimum; across many keywords, leave minutes between repeated requests to the same IP. Perfectly uniform timing is detectable on its own.
Spread across subnets. Google appears to evaluate reputation by subnet. A pool of 20 IPs in one /24 looks like a single noisy user to Google; the same 20 IPs across 6–8 subnets looks like a diverse residential mix. Choose pool size for subnet diversity rather than raw IP count.
Bench on a challenge, recover slowly. When an IP gets a CAPTCHA, pause it for hours, not minutes (raise bench_seconds accordingly in production). If challenges increase during a run, reduce the request rate; do not push harder.
Warm up cold IPs. IPs that have been idle for a week or more behave differently from IPs in daily rotation: reputation systems decay over time. Re-introduce dormant IPs at a fraction of normal throughput for a day or two, then increase gradually.
Match proxy geo to query geo. To track German rankings, use German-located IPs with gl=de. A US IP querying with gl=de is a mismatch that Google can detect and may treat as suspicious.
Cache and deduplicate. Do not re-check a keyword you checked an hour ago. Rankings do not change that quickly, and a browser render is much more expensive than a raw HTTP request.
Keep the parser isolated. When Google's markup shifts, the fix should stay in one file instead of becoming a debug session across the network and runner code.
Scaling the rank tracker
The architecture above handles a few hundred keywords. To go bigger:
Concurrency. Replace the sequential loop with several camoufox instances in parallel, but cap concurrency to 2 renders per subnet so you do not recreate the noisy-neighbor problem at scale. A browser per query is what reliably passes Google. The renders are RAM- and CPU-intensive, so match the number of workers to your hardware capacity. Parallel browser rendering is the workload our AMD EPYC servers are built for, if you outgrow a VPS.
Bigger proxy pools, sized by calculation. The same rule applies, and it is stricter now: more keywords and more pages per keyword require more IPs. Rough math (numbers vary by provider, query difficulty, and target geo; these are conservative defaults to start sizing from): each check is pages_per_keyword renders (~30 seconds each); a single IP can handle ~75–100 renders per day before block rate increases. So IPs needed ≈ (keywords × locations × pages) / 75, then double it for headroom (benched IPs, retries, subnet cooldowns). For 1,000 keywords × 3 locations × 2 pages daily, that is 6,000 / 75 = 80 IPs as the minimum, or ~160 in practice, spread across at least 6–8 subnets so a problem in one subnet does not disable half the pool. Our SEO proxy pools are sized along these dimensions.
A real queue. Move to Celery or RQ with Redis so checks are distributed, retried, and observable.
Postgres + a dashboard. Move from SQLite to Postgres and add Grafana or Metabase as a dashboard for live trend charts, including AI Overview coverage over time.
Mobile & local-pack tracking. Add a mobile fingerprint path and parse the local pack / map results for location-based SEO.
Run it for a week
Set the schedule, point the tracker at your production keywords, and let it run for seven days. The first few runs will give you the numbers that no article can predict, because they depend on your keywords, your locale, and your pool. You will see which of your queries trigger AI Overviews in your locale, which keywords are noisy by nature, and whether your block rate is below 5% (which is good) or above 15% (which usually means that your pool is too small, or your pacing is too tight). Tune the system with that data instead of your assumptions.
Google will eventually shift the markup, and the parser is the one component built to be rebuilt. When that day comes, the parse-failure bundle in _parse_failures/ has everything you need to fix one small file. The rest of the system keeps running while you do.
Every other part of this stack is code you now own. The proxy layer is the one part you cannot write yourself. If you want IPs that are sized for this workload, that is what our SEO proxies are built for: static, residential-grade ISP addresses across diverse subnets, with the block rates measured above (Cloudflare 0.06%, DataDome 0.2% over a 7-day production window) and Tier-1 ASN reputation from real consumer ISPs, running on our own infrastructure in Ashburn and Dallas.
If you build this and get stuck, our Discord is where the team answers questions.
FAQs
Are ISP proxies the same as residential proxies?
Yes and no. ISP proxies are classified as residential ISPs by reputation databases such as MaxMind, IPinfo, IP2Location, and IPQualityScore, because they carry the ASN of a real consumer ISP. The difference is the hosting. Traditional residential proxies route through a real person's home router, and lose the IP when that person closes their laptop. Sourcing your infrastructure from the best isp proxy provider ensures these IPs are hosted in a data center on the same ASN. Same residential trust score, far more stable connection.
Why does headless Chrome get blocked on Google?
Both vanilla and patched headless Chromium, such as Patchright and rebrowser, get blocked because the patches modify JavaScript properties post-hoc, and the modifications do not match what other detection signals (TLS fingerprint, HTTP/2 frame ordering, navigator timing) report. That inconsistency is what detection systems catch. Camoufox is Firefox-based and spoofs at the C++ level, which avoids that class of inconsistency.
What replaced Google's &num=100 parameter?
Google removed support for &num=100 in September 2025, and there is no direct replacement. You paginate with &start= instead (start=0 for results 1–10, start=10 for 11–20, and so on). This costs roughly 10× the requests for the same result depth, which is the reason a good proxy pool is now a practical requirement for any real depth.
How many ISP proxies do you need for SEO rank tracking?
It depends on keywords × locations × pages-per-keyword and the throughput a single IP can sustain (we use ~75–100 renders per day as a conservative default). For 1,000 keywords × 3 locations × 2 pages daily, that is roughly 160 IPs across 6–8 subnets, with headroom for benched IPs and retries. Our SEO proxies are sized for this kind of workload. See the Scaling section above for the full formula.