How To Monitor Walmart Prices In Python With ISP Proxies
Reliable Walmart price monitoring in Python usually comes down to two things: the TLS fingerprint of the request, and the reputation of the IP making it.
Gunnar
Last updated -
Why Hype Proxies
Walmart's anti-bot stack is mostly Akamai Bot Manager and HUMAN Security (which merged with PerimeterX in 2022). Some bot challenges return HTTP 200 with a challenge page in the body, so the status code alone is usually not enough to detect a block.
This guide uses curl_cffi to match the Chrome TLS handshake and ISP proxies for stable consumer-ISP reputation. The parser typically reads Walmart's embedded Next.js JSON blob. The monitor runs on a schedule and sends a Slack, Discord, or email alert when a price drops below a configured threshold.
TL;DR
curl_cffi with impersonate="chrome" typically passes Walmart's first Akamai check from a datacenter IP. Running the monitor over time usually needs ISP proxies, because the same IP making repeated requests typically gets flagged after a while.
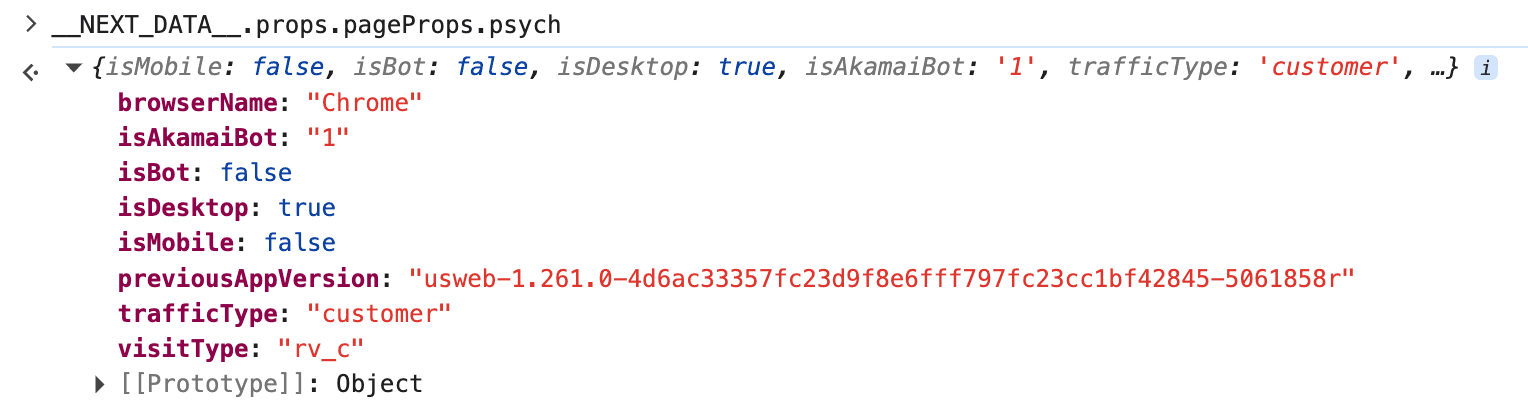
TLS impersonation usually passes the first request.curl_cffi mimics the Chrome TLS handshake. Walmart's server-side classifier labels matching fingerprints as trafficType: "customer", visible in the embedded psych diagnostic object on the product page (screenshot below). Even datacenter IPs often get this label on the first request. The standard Python requests library produces a TLS fingerprint (from urllib3 underneath) that Akamai usually detects right away.
ISP proxies usually keep the monitor working over time. A single IP making dozens of requests per day on the same product pages typically collects reputation flags. Cycling through a pool of consumer-ISP IPs usually keeps the per-IP rate below Akamai's behavioral thresholds.
Monthly cost. $65/month for the ISP proxy plan. Deployment adds $5/month on a small VPS, or $0 on GitHub Actions.
Price extraction. Walmart typically embeds most of the pricing payload in a Next.js JSON blob at <script id="__NEXT_DATA__">. The parser reads the price object from there. Walmart does not expose price data in JSON-LD or Open Graph meta tags on product pages, and there is no public API for unauthenticated reads. In our testing, the JSON blob is the most reliable source. CSS selectors stay as a fallback for missing or restructured blobs.
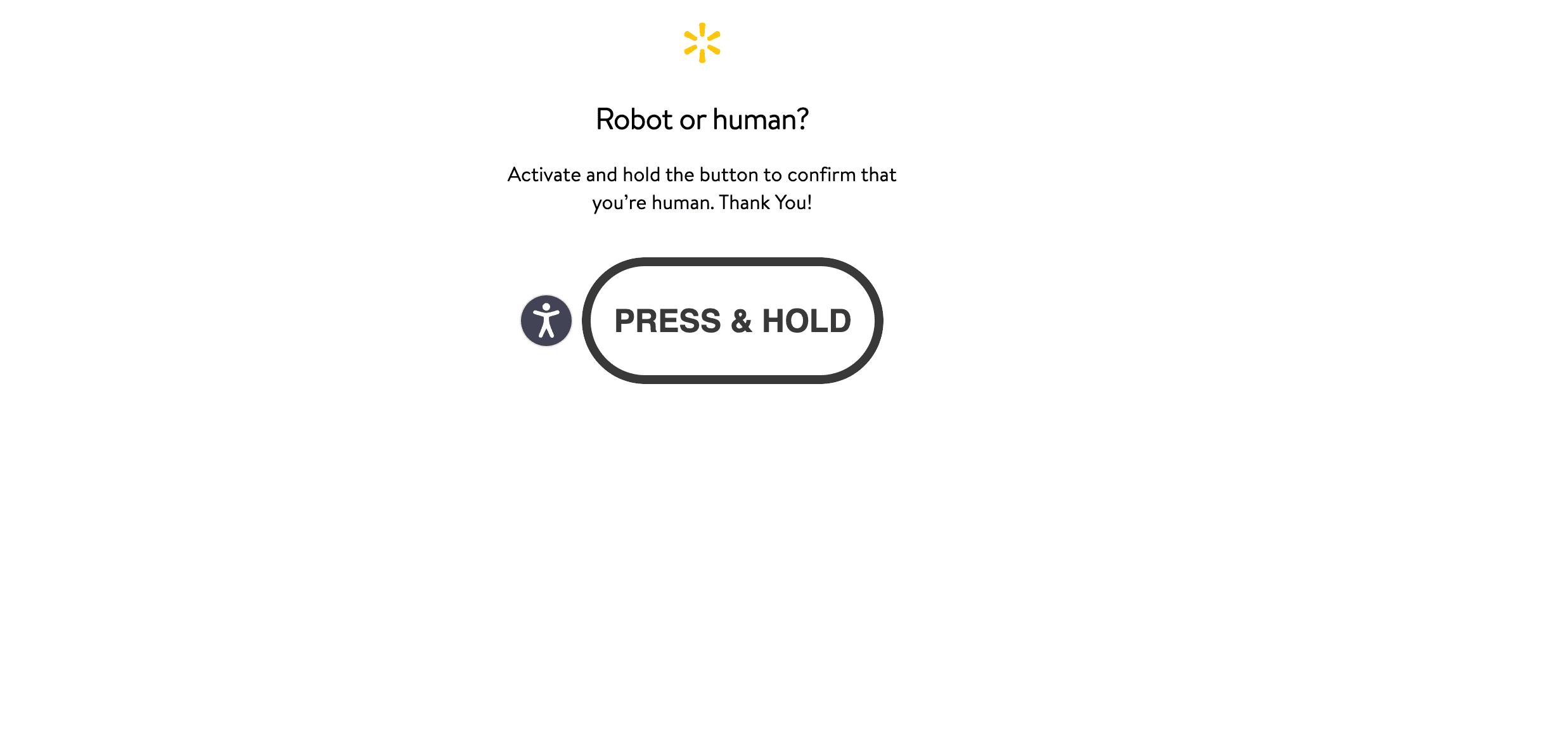
Two main challenge variants. A soft challenge typically returns HTTP 200 with an "Activate and hold" Press & Hold body, so the scraper needs to check the body, not just the status code. A hard block typically returns HTTP 307 redirecting to /blocked?url=<base64>. Both trigger a retry through the next proxy.
Suitable for: monitoring a few hundred products at hourly cadence on www.walmart.com with the sequential scraper. The async variant in Scaling and adapting raises this to a few thousand. The same setup usually works on walmart.ca and walmart.com.mx with some changes.
Not suitable for: JS-gated pricing (some pharmacy or service items). For those, use a headless browser instead. The setup is also not suitable for bulk one-shot scrapes of 100,000+ products. The Walmart Marketplace API is for sellers managing their own listings, not third-party price monitoring.
Prerequisites
Full setup takes 30 to 45 minutes once ISP proxies are available.
Python 3.10 or newer and a machine that stays on. A small Linux VPS at $5/month is usually enough. See Deploy continuously for alternatives.
An ISP proxy pool. An ISP proxy (also called a static residential proxy) is a fixed IP address owned by a consumer ISP such as AT&T or Frontier. It is not a datacenter IP or a rotating residential pool that typically changes IP every few minutes. We use HypeProxies ISP proxies for the setup in this guide. The IPs come directly from consumer ISP partnerships, not resold residential pools. The entry plan is $65/month for 50 IPs with unlimited bandwidth.
A Slack workspace (or any other notification channel supported by the Apprise library, explained in Step 6). Slack is the default because incoming webhooks are usually quick to set up. Other channels typically work with a line of configuration.
ISP proxies work here mostly because Walmart's Akamai stack classifies IPs by ASN (Autonomous System Number). Datacenter ASNs such as AWS, OVH, Hetzner, or DigitalOcean trigger the Akamai challenge on most Walmart requests over time, even with the right TLS fingerprint. Consumer-ISP ASNs pass more often.
Testing without proxies. For sanity-checking the stack on a fresh machine, leave PROXIES unset and the scraper runs in direct mode via curl_cffi's TLS impersonation. This works for a few dozen products at hourly cadence as a quick test. Production monitoring usually needs the ISP proxy pool. Akamai typically starts flagging the IP after a few cycles of sustained traffic.
Per-IP pricing. ISP proxies are billed per IP, so cost stays flat as traffic grows. Per-GB residential pricing (usually a few dollars per GB at smaller volumes) typically scales linearly with traffic. It usually gets expensive for hourly monitoring. A few hundred products checked hourly can transfer tens of GB per month. See owning vs renting proxies for the cost math at scale, or our head-to-head with the major ISP providers if you're comparing vendors directly.
Why curl_cffi.curl_cffi has the same API as requests, so usually only the import statement changes. Do not set User-Agent or other headers manually. curl_cffi already sets them. If you override them, the fingerprint usually stops matching the browser profile.
Step 2: Configure proxies and products
The scraper needs 2 more inputs: a proxy pool and a product list. If you don't have ISP proxies yet, sign up at HypeProxies and get your credentials from the dashboard. They come in IP:PORT:USERNAME:PASSWORD format:
Save them one per line in a file like proxies.txt. The scraper reads them from the PROXIES env var, set with PROXIES="$(cat proxies.txt)" (Step 7 shows the full command).
Three main properties matter for an ISP proxy pool:
Static IPs, not "rotating residential" sessions. Static IPs typically build a clean request history at Walmart. Rotating residential sessions often return a different IP every few minutes.
US-based, owned by a consumer ISP. Check the ASN with whois <ip> (the OriginAS or origin: field in the output) or our proxy checker. Frontier, AT&T, and RCN are consumer-ISP networks. AWS and OVH are datacenter networks. Walmart usually flags these fast.
Unlimited bandwidth, billed per IP rather than per GB. Per-GB pricing typically scales linearly with traffic. Hourly monitoring usually gets expensive fast.
Beyond ASN, run any IP through our proxy checker (no signup) for fraud score, hostname, geolocation, VPN/Proxy/Tor detection, WebRTC/DNS leak detection, and live speed tests to Amazon, Google, and YouTube. This usually confirms an IP is a consumer-ISP IP and not a datacenter IP sold as residential.
Create config.py. Pydantic validates the config at load time. An item ID with the wrong format fails before the scraper sends any request.
# config.pyimportosimportrefromurllib.parseimportquotefrompydantic importBaseModel,field_validatorclass ProxyConfig(BaseModel):
host:str
port:str #str(not int)so it goes straight into the URL f-string below
user:str
password:str
@propertydef url(self):
# URL-escape user/pass so '@'or ':'inside credentials donot breakparsing.
returnf"http://{quote(self.user, safe='')}:{quote(self.password, safe='')}@{self.host}:{self.port}"class ProductConfig(BaseModel):
item_id:str
name:str
@field_validator("item_id")
@classmethoddef validate_item_id(cls,v):
# Walmart item IDs are numeric,typically 6to 12digits. Regexstays
# loose at 5to 15to cover outliers.
ifnot re.fullmatch(r"\d{5,15}",v):raise ValueError("item_id must be a numeric string of 5 to 15 digits")returnvdef _load_proxies_from_env():raw = os.environ.get("PROXIES","").strip()ifnot raw:
# Empty PROXIES = direct mode(curl_cffi TLSimpersonationonly).
# Usefulforquick testing. Productionneeds ISP proxies.
return[]proxies = []forlineinraw.splitlines():line = line.strip()ifnot line:continue
# maxsplit=3keeps any ':'inside the password intact.
parts = line.split(":",3)iflen(parts) != 4:raise ValueError(f"Bad proxy line (expected host:port:user:pass): {line}")host,port,user,password = partsproxies.append(ProxyConfig(host=host,port=port,user=user,password=password))returnproxiesPROXIES = _load_proxies_from_env()REQUEST_TIMEOUT = 15MAX_RETRIES = 3
# config.pyimportosimportrefromurllib.parseimportquotefrompydantic importBaseModel,field_validatorclass ProxyConfig(BaseModel):
host:str
port:str #str(not int)so it goes straight into the URL f-string below
user:str
password:str
@propertydef url(self):
# URL-escape user/pass so '@'or ':'inside credentials donot breakparsing.
returnf"http://{quote(self.user, safe='')}:{quote(self.password, safe='')}@{self.host}:{self.port}"class ProductConfig(BaseModel):
item_id:str
name:str
@field_validator("item_id")
@classmethoddef validate_item_id(cls,v):
# Walmart item IDs are numeric,typically 6to 12digits. Regexstays
# loose at 5to 15to cover outliers.
ifnot re.fullmatch(r"\d{5,15}",v):raise ValueError("item_id must be a numeric string of 5 to 15 digits")returnvdef _load_proxies_from_env():raw = os.environ.get("PROXIES","").strip()ifnot raw:
# Empty PROXIES = direct mode(curl_cffi TLSimpersonationonly).
# Usefulforquick testing. Productionneeds ISP proxies.
return[]proxies = []forlineinraw.splitlines():line = line.strip()ifnot line:continue
# maxsplit=3keeps any ':'inside the password intact.
parts = line.split(":",3)iflen(parts) != 4:raise ValueError(f"Bad proxy line (expected host:port:user:pass): {line}")host,port,user,password = partsproxies.append(ProxyConfig(host=host,port=port,user=user,password=password))returnproxiesPROXIES = _load_proxies_from_env()REQUEST_TIMEOUT = 15MAX_RETRIES = 3
# config.pyimportosimportrefromurllib.parseimportquotefrompydantic importBaseModel,field_validatorclass ProxyConfig(BaseModel):
host:str
port:str #str(not int)so it goes straight into the URL f-string below
user:str
password:str
@propertydef url(self):
# URL-escape user/pass so '@'or ':'inside credentials donot breakparsing.
returnf"http://{quote(self.user, safe='')}:{quote(self.password, safe='')}@{self.host}:{self.port}"class ProductConfig(BaseModel):
item_id:str
name:str
@field_validator("item_id")
@classmethoddef validate_item_id(cls,v):
# Walmart item IDs are numeric,typically 6to 12digits. Regexstays
# loose at 5to 15to cover outliers.
ifnot re.fullmatch(r"\d{5,15}",v):raise ValueError("item_id must be a numeric string of 5 to 15 digits")returnvdef _load_proxies_from_env():raw = os.environ.get("PROXIES","").strip()ifnot raw:
# Empty PROXIES = direct mode(curl_cffi TLSimpersonationonly).
# Usefulforquick testing. Productionneeds ISP proxies.
return[]proxies = []forlineinraw.splitlines():line = line.strip()ifnot line:continue
# maxsplit=3keeps any ':'inside the password intact.
parts = line.split(":",3)iflen(parts) != 4:raise ValueError(f"Bad proxy line (expected host:port:user:pass): {line}")host,port,user,password = partsproxies.append(ProxyConfig(host=host,port=port,user=user,password=password))returnproxiesPROXIES = _load_proxies_from_env()REQUEST_TIMEOUT = 15MAX_RETRIES = 3
Create products.json. Each entry needs 2 fields: item_id and name. The item_id is the numeric ID at the end of a Walmart product URL:
{"products":[{"item_id":"11381374703","name":"Apple AirPods 4"},{"item_id":"11384707978","name":"Apple AirPods 4 with Active Noise Cancellation"}]}
{"products":[{"item_id":"11381374703","name":"Apple AirPods 4"},{"item_id":"11384707978","name":"Apple AirPods 4 with Active Noise Cancellation"}]}
{"products":[{"item_id":"11381374703","name":"Apple AirPods 4"},{"item_id":"11384707978","name":"Apple AirPods 4 with Active Noise Cancellation"}]}
A URL like https://www.walmart.com/ip/Apple-AirPods-4/11381374703 has item ID 11381374703. The product-name slug is optional. Walmart typically redirects /ip/<id> to the full URL with the slug.
Step 3: Proxy diagnostic
Verify the proxy pool before continuing to the scraper code. This script checks two things: each proxy is reachable, and curl_cffi routes through it. Create test_proxies.py:
# test_proxies.pyimporttimefromcurl_cffi import requests as curl_requests
from config importPROXIESfori,proxyinenumerate(PROXIES,1):try:t0 = time.time()r = curl_requests.get("https://httpbin.org/ip",proxy=proxy.url,timeout=10,impersonate="chrome",)elapsed = time.time() - t0print(f"Proxy {i}: {r.json()['origin']} - OK ({elapsed:.2f}s)")except Exceptionas e:print(f"Proxy{i}:FAILED - {e}")
# test_proxies.pyimporttimefromcurl_cffi import requests as curl_requests
from config importPROXIESfori,proxyinenumerate(PROXIES,1):try:t0 = time.time()r = curl_requests.get("https://httpbin.org/ip",proxy=proxy.url,timeout=10,impersonate="chrome",)elapsed = time.time() - t0print(f"Proxy {i}: {r.json()['origin']} - OK ({elapsed:.2f}s)")except Exceptionas e:print(f"Proxy{i}:FAILED - {e}")
# test_proxies.pyimporttimefromcurl_cffi import requests as curl_requests
from config importPROXIESfori,proxyinenumerate(PROXIES,1):try:t0 = time.time()r = curl_requests.get("https://httpbin.org/ip",proxy=proxy.url,timeout=10,impersonate="chrome",)elapsed = time.time() - t0print(f"Proxy {i}: {r.json()['origin']} - OK ({elapsed:.2f}s)")except Exceptionas e:print(f"Proxy{i}:FAILED - {e}")
Run it with the PROXIES env var set: PROXIES="$(cat proxies.txt)" python test_proxies.py. Output should look like:
The IPs should be different from each other. Sub-2-second responses are typical.
If any line says FAILED, fix that proxy before continuing. Usually this is wrong credentials or a port that is not yet active. To check a single IP outside this script, run it through our proxy checker for reachability, ASN, and fraud score.
Step 4: Build the scraper
The scraper has 4 jobs: TLS impersonation, cycling through the proxy pool, detecting Walmart challenge variants, and pulling the price from the Next.js JSON blob. The three sub-sections below walk through scraper.py part by part.
Schema and the markers that detect challenges
# scraper.pyimportjsonimportrandomimporttimefromdatetime import datetime
from itertools importcyclefromcurl_cffi import requests as curl_requests
from bs4 importBeautifulSoupfromtenacity import retry, stop_after_attempt, wait_random, retry_if_exception_type
from loguru importloggerfrompydantic import BaseModel, Field
from config importPROXIES,REQUEST_TIMEOUT,MAX_RETRIESclass PriceResult(BaseModel):
item_id:str
title:str
brand:str | None = None
price:float | None = None
was_price:float | None = None
list_price:float | None = None
unit_price_display:str | None = None
buybox_price_display:str | None = None
is_reduced:bool = False
offer_type:str | None = None
seller_name:str | None = None
seller_type:str | None = None
availability:str = "Unknown"
availability_code:str | None = None
rating:str | None = None
review_count:int | None = None
is_price_event:bool = False
timestamp:datetime = Field(default_factory=datetime.now)class RetryableError(Exception):"""Raised on transient failures (5xx, 429, challenge). Triggers a retry. Permanent errors raise plain Exception."""NEXT_DATA_SELECTOR = "script#__NEXT_DATA__"
# Narrow markers only. "perimeterx" / "px-captcha"false-positive on real
# product pages because Walmart's CSP meta tag lists *.perimeterx.net.
CHALLENGE_MARKERS = ("activate and hold the button","<title>robot or human",)BLOCKED_PATH = "/blocked"PRICE_SELECTORS = ['[itemprop="price"]','[data-automation-id="product-price"] span.f1','span[data-testid="price-wrap"]','span[data-seo-id="hero-price"]',]
# scraper.pyimportjsonimportrandomimporttimefromdatetime import datetime
from itertools importcyclefromcurl_cffi import requests as curl_requests
from bs4 importBeautifulSoupfromtenacity import retry, stop_after_attempt, wait_random, retry_if_exception_type
from loguru importloggerfrompydantic import BaseModel, Field
from config importPROXIES,REQUEST_TIMEOUT,MAX_RETRIESclass PriceResult(BaseModel):
item_id:str
title:str
brand:str | None = None
price:float | None = None
was_price:float | None = None
list_price:float | None = None
unit_price_display:str | None = None
buybox_price_display:str | None = None
is_reduced:bool = False
offer_type:str | None = None
seller_name:str | None = None
seller_type:str | None = None
availability:str = "Unknown"
availability_code:str | None = None
rating:str | None = None
review_count:int | None = None
is_price_event:bool = False
timestamp:datetime = Field(default_factory=datetime.now)class RetryableError(Exception):"""Raised on transient failures (5xx, 429, challenge). Triggers a retry. Permanent errors raise plain Exception."""NEXT_DATA_SELECTOR = "script#__NEXT_DATA__"
# Narrow markers only. "perimeterx" / "px-captcha"false-positive on real
# product pages because Walmart's CSP meta tag lists *.perimeterx.net.
CHALLENGE_MARKERS = ("activate and hold the button","<title>robot or human",)BLOCKED_PATH = "/blocked"PRICE_SELECTORS = ['[itemprop="price"]','[data-automation-id="product-price"] span.f1','span[data-testid="price-wrap"]','span[data-seo-id="hero-price"]',]
# scraper.pyimportjsonimportrandomimporttimefromdatetime import datetime
from itertools importcyclefromcurl_cffi import requests as curl_requests
from bs4 importBeautifulSoupfromtenacity import retry, stop_after_attempt, wait_random, retry_if_exception_type
from loguru importloggerfrompydantic import BaseModel, Field
from config importPROXIES,REQUEST_TIMEOUT,MAX_RETRIESclass PriceResult(BaseModel):
item_id:str
title:str
brand:str | None = None
price:float | None = None
was_price:float | None = None
list_price:float | None = None
unit_price_display:str | None = None
buybox_price_display:str | None = None
is_reduced:bool = False
offer_type:str | None = None
seller_name:str | None = None
seller_type:str | None = None
availability:str = "Unknown"
availability_code:str | None = None
rating:str | None = None
review_count:int | None = None
is_price_event:bool = False
timestamp:datetime = Field(default_factory=datetime.now)class RetryableError(Exception):"""Raised on transient failures (5xx, 429, challenge). Triggers a retry. Permanent errors raise plain Exception."""NEXT_DATA_SELECTOR = "script#__NEXT_DATA__"
# Narrow markers only. "perimeterx" / "px-captcha"false-positive on real
# product pages because Walmart's CSP meta tag lists *.perimeterx.net.
CHALLENGE_MARKERS = ("activate and hold the button","<title>robot or human",)BLOCKED_PATH = "/blocked"PRICE_SELECTORS = ['[itemprop="price"]','[data-automation-id="product-price"] span.f1','span[data-testid="price-wrap"]','span[data-seo-id="hero-price"]',]
PriceResult holds every field the parser pulls from the JSON blob, because they all come from one place on the page.
An earlier version of the scraper used 4 markers in CHALLENGE_MARKERS including "perimeterx" and "px-captcha". Walmart sends its CSP policy as a <meta http-equiv="Content-Security-Policy"> tag in the response body. The tag lists *.perimeterx.net, *.px-cdn.net, and similar HUMAN Security domains on the product pages we fetched. The body-text scan matched those strings on essentially every successful fetch and treated valid responses as challenges.
The 2 markers above are specific to the challenge page: "activate and hold the button" (the Press & Hold UI text) and "<title>robot or human" (the title tag on the challenge page).
Retry only on errors a new IP can fix
class WalmartPriceScraper:
def __init__(self):
# Shuffle on startup so a burned proxy is not first on every run.
# EmptyPROXIES = direct mode.
self._proxy_pool = cycle(random.sample(PROXIES,len(PROXIES)))ifPROXIES elseNoneifself._proxy_poolis None:logger.warning("No PROXIES configured; running in direct mode. ""Akamai may flag this IP after sustained requests.")def _get_next_proxy(self):ifself._proxy_poolis None:returnNonereturnnext(self._proxy_pool).url
@retry(stop=stop_after_attempt(MAX_RETRIES),wait=wait_random(min=3,max=10),retry=retry_if_exception_type(RetryableError),)def fetch_product_page(self,item_id):url = f"https://www.walmart.com/ip/{item_id}"proxy = self._get_next_proxy()kwargs = {"timeout":REQUEST_TIMEOUT,"impersonate":"chrome"}ifproxy is not None:kwargs["proxy"] = proxyresponse = curl_requests.get(url, **kwargs)
# 404 = product delisted. Noretry.
ifresponse.status_code == 404:logger.warning(f"Product {item_id} not found (404)")returnNone
# Transient:retry on next proxy.
ifresponse.status_code == 429:raise RetryableError(f"Rate limited (429) for {item_id}")if500 <= response.status_code < 600:raise RetryableError(f"Server error {response.status_code} for {item_id}")
# Hard block:307 -> /blocked?url=<base64>. curl_cffi follows redirects by default, so we check the final URL.ifBLOCKED_PATHin(response.urlor ""):
raise RetryableError(f"Akamaihard block(/blocked) for {item_id}")ifresponse.status_code != 200:raise Exception(f"Permanent HTTP error {response.status_code} for {item_id}")
# Soft challenge returns 200withchallenge body. Statusalone is not enough.
body_lower = response.text.lower()formarkerinCHALLENGE_MARKERS:ifmarkerinbody_lower:raise RetryableError(f"Bot challenge ({marker!r}) for {item_id}")returnresponse.text
class WalmartPriceScraper:
def __init__(self):
# Shuffle on startup so a burned proxy is not first on every run.
# EmptyPROXIES = direct mode.
self._proxy_pool = cycle(random.sample(PROXIES,len(PROXIES)))ifPROXIES elseNoneifself._proxy_poolis None:logger.warning("No PROXIES configured; running in direct mode. ""Akamai may flag this IP after sustained requests.")def _get_next_proxy(self):ifself._proxy_poolis None:returnNonereturnnext(self._proxy_pool).url
@retry(stop=stop_after_attempt(MAX_RETRIES),wait=wait_random(min=3,max=10),retry=retry_if_exception_type(RetryableError),)def fetch_product_page(self,item_id):url = f"https://www.walmart.com/ip/{item_id}"proxy = self._get_next_proxy()kwargs = {"timeout":REQUEST_TIMEOUT,"impersonate":"chrome"}ifproxy is not None:kwargs["proxy"] = proxyresponse = curl_requests.get(url, **kwargs)
# 404 = product delisted. Noretry.
ifresponse.status_code == 404:logger.warning(f"Product {item_id} not found (404)")returnNone
# Transient:retry on next proxy.
ifresponse.status_code == 429:raise RetryableError(f"Rate limited (429) for {item_id}")if500 <= response.status_code < 600:raise RetryableError(f"Server error {response.status_code} for {item_id}")
# Hard block:307 -> /blocked?url=<base64>. curl_cffi follows redirects by default, so we check the final URL.ifBLOCKED_PATHin(response.urlor ""):
raise RetryableError(f"Akamaihard block(/blocked) for {item_id}")ifresponse.status_code != 200:raise Exception(f"Permanent HTTP error {response.status_code} for {item_id}")
# Soft challenge returns 200withchallenge body. Statusalone is not enough.
body_lower = response.text.lower()formarkerinCHALLENGE_MARKERS:ifmarkerinbody_lower:raise RetryableError(f"Bot challenge ({marker!r}) for {item_id}")returnresponse.text
class WalmartPriceScraper:
def __init__(self):
# Shuffle on startup so a burned proxy is not first on every run.
# EmptyPROXIES = direct mode.
self._proxy_pool = cycle(random.sample(PROXIES,len(PROXIES)))ifPROXIES elseNoneifself._proxy_poolis None:logger.warning("No PROXIES configured; running in direct mode. ""Akamai may flag this IP after sustained requests.")def _get_next_proxy(self):ifself._proxy_poolis None:returnNonereturnnext(self._proxy_pool).url
@retry(stop=stop_after_attempt(MAX_RETRIES),wait=wait_random(min=3,max=10),retry=retry_if_exception_type(RetryableError),)def fetch_product_page(self,item_id):url = f"https://www.walmart.com/ip/{item_id}"proxy = self._get_next_proxy()kwargs = {"timeout":REQUEST_TIMEOUT,"impersonate":"chrome"}ifproxy is not None:kwargs["proxy"] = proxyresponse = curl_requests.get(url, **kwargs)
# 404 = product delisted. Noretry.
ifresponse.status_code == 404:logger.warning(f"Product {item_id} not found (404)")returnNone
# Transient:retry on next proxy.
ifresponse.status_code == 429:raise RetryableError(f"Rate limited (429) for {item_id}")if500 <= response.status_code < 600:raise RetryableError(f"Server error {response.status_code} for {item_id}")
# Hard block:307 -> /blocked?url=<base64>. curl_cffi follows redirects by default, so we check the final URL.ifBLOCKED_PATHin(response.urlor ""):
raise RetryableError(f"Akamaihard block(/blocked) for {item_id}")ifresponse.status_code != 200:raise Exception(f"Permanent HTTP error {response.status_code} for {item_id}")
# Soft challenge returns 200withchallenge body. Statusalone is not enough.
body_lower = response.text.lower()formarkerinCHALLENGE_MARKERS:ifmarkerinbody_lower:raise RetryableError(f"Bot challenge ({marker!r}) for {item_id}")returnresponse.text
The retry layer above handles soft challenges and hard blocks. ISP proxies cut the rate of Akamai challenges compared to datacenter IPs. Even within the ISP category, quality varies.
You will still see CAPTCHAs and 429s sometimes, even with good consumer-ISP proxies.
impersonate="chrome" makes the TLS fingerprint look like Chrome traffic. Without it, Akamai returns the hard block on almost every request. With it, you typically get HTTP 200 responses with valid product pages, even from a datacenter IP.
The retry policy treats failure types differently. Only RetryableError triggers a retry (5xx, 429, hard block, soft challenge). A 404 returns None. Other 4xx responses raise a plain Exception and stop the loop. Each retry moves to the next proxy.
One JSON blob with the price fields
The helper functions below sit at module scope. The class methods that follow them belong to the same WalmartPriceScraper class started above. Add them to that class in your scraper.py file.
def _coerce_price(node):"""Return float price from a Walmart price node, or None when absent or malformed."""ifnot isinstance(node,dict):returnNoneprice = node.get("price")ifprice is None:returnNonetry:returnfloat(price)except(TypeError,ValueError):returnNonedef _extract_offer_type(price_display_codes):"""Return the most specific offer flag, or None."""ifnot isinstance(price_display_codes,dict):returnNoneforkeyin("rollback","clearance","reducedPrice"):ifprice_display_codes.get(key):returnkeyreturnNonedef extract_price_text(tag):"""Parse a float price from a BeautifulSoup tag (CSS fallback path)."""iftag is None:returnNonetext = tag.get("content")or tag.get_text(strip=True)ifnot text:returnNonetry:returnfloat(str(text).replace("$","").replace(",","").strip())except(ValueError,TypeError):returnNone
def _coerce_price(node):"""Return float price from a Walmart price node, or None when absent or malformed."""ifnot isinstance(node,dict):returnNoneprice = node.get("price")ifprice is None:returnNonetry:returnfloat(price)except(TypeError,ValueError):returnNonedef _extract_offer_type(price_display_codes):"""Return the most specific offer flag, or None."""ifnot isinstance(price_display_codes,dict):returnNoneforkeyin("rollback","clearance","reducedPrice"):ifprice_display_codes.get(key):returnkeyreturnNonedef extract_price_text(tag):"""Parse a float price from a BeautifulSoup tag (CSS fallback path)."""iftag is None:returnNonetext = tag.get("content")or tag.get_text(strip=True)ifnot text:returnNonetry:returnfloat(str(text).replace("$","").replace(",","").strip())except(ValueError,TypeError):returnNone
def _coerce_price(node):"""Return float price from a Walmart price node, or None when absent or malformed."""ifnot isinstance(node,dict):returnNoneprice = node.get("price")ifprice is None:returnNonetry:returnfloat(price)except(TypeError,ValueError):returnNonedef _extract_offer_type(price_display_codes):"""Return the most specific offer flag, or None."""ifnot isinstance(price_display_codes,dict):returnNoneforkeyin("rollback","clearance","reducedPrice"):ifprice_display_codes.get(key):returnkeyreturnNonedef extract_price_text(tag):"""Parse a float price from a BeautifulSoup tag (CSS fallback path)."""iftag is None:returnNonetext = tag.get("content")or tag.get_text(strip=True)ifnot text:returnNonetry:returnfloat(str(text).replace("$","").replace(",","").strip())except(ValueError,TypeError):returnNone
The main parser uses the helpers above to walk the JSON path. The methods below continue the same WalmartPriceScraper class started in the previous sub-section.
wo more methods finish the class. The CSS fallback runs when the JSON blob is missing; get_price orchestrates the fetch + parse cycle (still in the same class as above).
class WalmartPriceScraper:
# ... (continued fromabove)def parse_price_from_css(self,soup):"""Fallback parser used only if __NEXT_DATA__ is missing."""forselectorinPRICE_SELECTORS:price = extract_price_text(soup.select_one(selector))ifprice is not None:returnpricereturnNonedef parse_product_info(self,html,item_id):soup = BeautifulSoup(html,"lxml")parsed = self.parse_from_next_data(soup)ifparsed is not None:returnPriceResult(item_id=item_id, **parsed)
# CSS fallback:reached only ifWalmart removes or restructures __NEXT_DATA__.
logger.warning(f"__NEXT_DATA__ missing for {item_id}; falling back to CSS")title_tag = soup.select_one("h1[itemprop='name']")or soup.select_one("h1")title = title_tag.get_text(strip=True)iftitle_tag else"Unknown"price = self.parse_price_from_css(soup)returnPriceResult(item_id=item_id,title=title,price=price)def get_price(self,item_id):
# Random delay breaks the uniform request-timing pattern anti-bot systems flag on.
# Livesoutside fetch_product_page so it does not stack withthe retry wait.
time.sleep(random.uniform(3,7))
# Catch RetryableError only. Permanent4xx raises plain Exception
# and must surface to the caller,not get swallowed here.
try:html = self.fetch_product_page(item_id)except RetryableErroras e:logger.error(f"Retries exhausted for {item_id}: {e}")returnNoneifhtml is None:returnNonereturnself.parse_product_info(html,item_id)
class WalmartPriceScraper:
# ... (continued fromabove)def parse_price_from_css(self,soup):"""Fallback parser used only if __NEXT_DATA__ is missing."""forselectorinPRICE_SELECTORS:price = extract_price_text(soup.select_one(selector))ifprice is not None:returnpricereturnNonedef parse_product_info(self,html,item_id):soup = BeautifulSoup(html,"lxml")parsed = self.parse_from_next_data(soup)ifparsed is not None:returnPriceResult(item_id=item_id, **parsed)
# CSS fallback:reached only ifWalmart removes or restructures __NEXT_DATA__.
logger.warning(f"__NEXT_DATA__ missing for {item_id}; falling back to CSS")title_tag = soup.select_one("h1[itemprop='name']")or soup.select_one("h1")title = title_tag.get_text(strip=True)iftitle_tag else"Unknown"price = self.parse_price_from_css(soup)returnPriceResult(item_id=item_id,title=title,price=price)def get_price(self,item_id):
# Random delay breaks the uniform request-timing pattern anti-bot systems flag on.
# Livesoutside fetch_product_page so it does not stack withthe retry wait.
time.sleep(random.uniform(3,7))
# Catch RetryableError only. Permanent4xx raises plain Exception
# and must surface to the caller,not get swallowed here.
try:html = self.fetch_product_page(item_id)except RetryableErroras e:logger.error(f"Retries exhausted for {item_id}: {e}")returnNoneifhtml is None:returnNonereturnself.parse_product_info(html,item_id)
class WalmartPriceScraper:
# ... (continued fromabove)def parse_price_from_css(self,soup):"""Fallback parser used only if __NEXT_DATA__ is missing."""forselectorinPRICE_SELECTORS:price = extract_price_text(soup.select_one(selector))ifprice is not None:returnpricereturnNonedef parse_product_info(self,html,item_id):soup = BeautifulSoup(html,"lxml")parsed = self.parse_from_next_data(soup)ifparsed is not None:returnPriceResult(item_id=item_id, **parsed)
# CSS fallback:reached only ifWalmart removes or restructures __NEXT_DATA__.
logger.warning(f"__NEXT_DATA__ missing for {item_id}; falling back to CSS")title_tag = soup.select_one("h1[itemprop='name']")or soup.select_one("h1")title = title_tag.get_text(strip=True)iftitle_tag else"Unknown"price = self.parse_price_from_css(soup)returnPriceResult(item_id=item_id,title=title,price=price)def get_price(self,item_id):
# Random delay breaks the uniform request-timing pattern anti-bot systems flag on.
# Livesoutside fetch_product_page so it does not stack withthe retry wait.
time.sleep(random.uniform(3,7))
# Catch RetryableError only. Permanent4xx raises plain Exception
# and must surface to the caller,not get swallowed here.
try:html = self.fetch_product_page(item_id)except RetryableErroras e:logger.error(f"Retries exhausted for {item_id}: {e}")returnNoneifhtml is None:returnNonereturnself.parse_product_info(html,item_id)
Here is what the parser reads from a live Walmart product page:
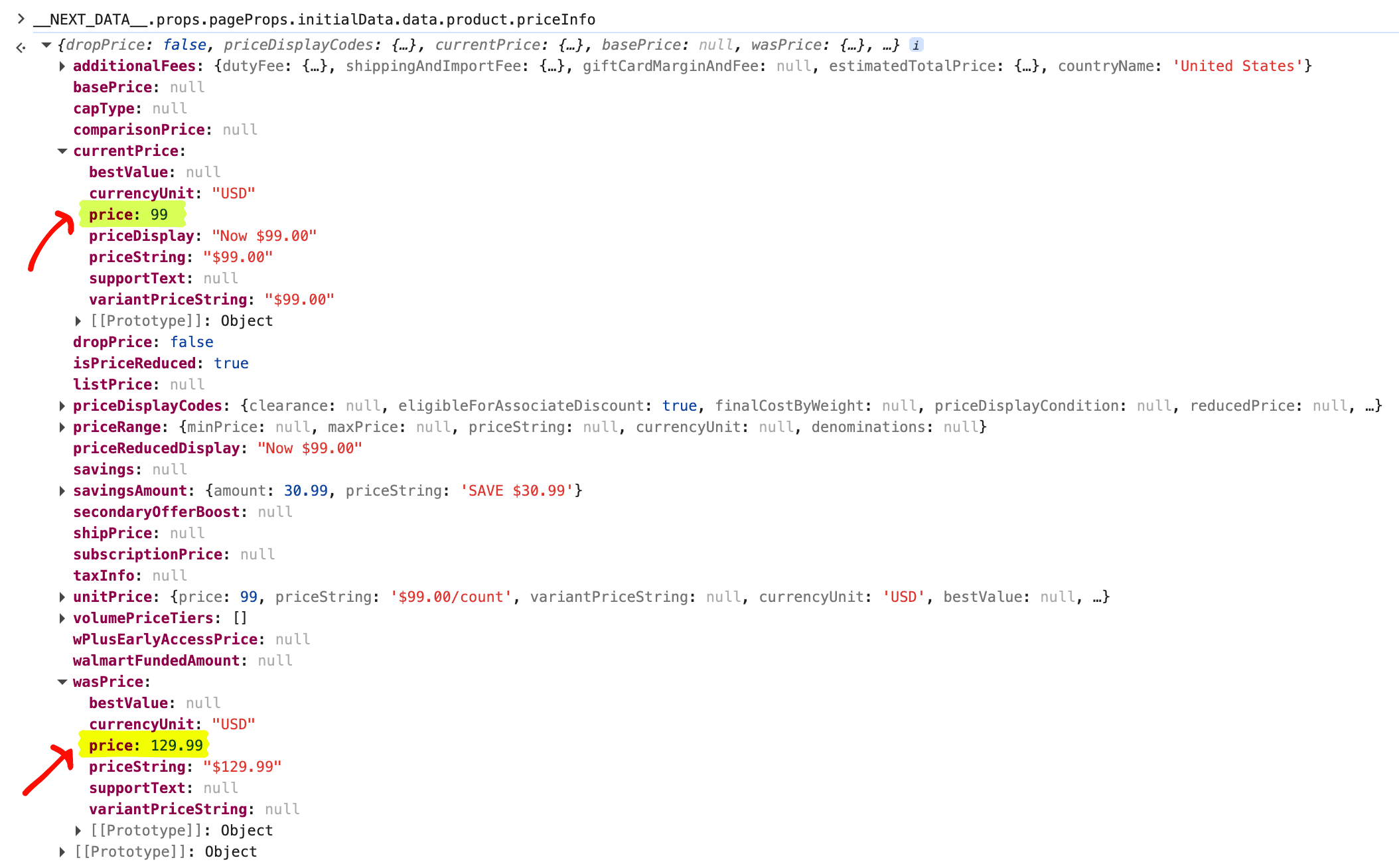
currentPrice.price is typically a number, not a string. In our testing you do not need to strip the dollar sign. The formatted string is in currentPrice.priceString for display.
wasPrice is usually populated when Walmart shows a strikethrough old price. It matches the shape of currentPrice. When there is no prior price, the field is typically null. listPrice (MSRP) uses the same shape when present.
unitPrice is set for many product categories. It usually includes a pre-formatted display string like $99.00/count for single-unit items or $1.14/100 ct for multi-unit groceries, so in most cases you can drop it into alerts.
priceDisplayCodes has Walmart's offer flags (rollback, clearance, reducedPrice). The isPriceReduced boolean next to it is typically true when the page shows a markdown badge.
The parser also reads sellerName, sellerType, availabilityStatusV2, topBoostedOffer.priceString, and eventAttributes. These typically live at the product level (one level up from priceInfo) and cover marketplace info, stock status, and short-term sale events.
Step 5: Storage and decision layer
Each PriceResult from the scraper feeds the decision layer. It runs three checks on a new reading: a 24-hour baseline low, a drop-size threshold (2% AND $1), and a per-product cooldown. Readings are stored in TinyDB, a JSON-backed key-value store that runs in-process with no server.
# storage.pyfrom datetime importdatetime,timedeltafromloguru import logger
from tinydb importQueryMIN_DROP_PCT = 2.0MIN_DROP_DOLLARS = 1.00COOLDOWN_HOURS = 6BASELINE_WINDOW_HOURS = 24HISTORY_RETENTION_DAYS = 30def prune_old_entries(db,retention_days=HISTORY_RETENTION_DAYS):"""Delete readings older than retention_days so the file does not grow without limit."""P = Query()cutoff = (datetime.now() - timedelta(days=retention_days)).isoformat()removed = db.remove(P.timestamp < cutoff)if removed:logger.info(f"Pruned {len(removed)} entries older than {retention_days}d")def get_baseline_price(db,item_id,window_hours=BASELINE_WINDOW_HOURS):"""Return the lowest price seen for this item_id in the last window_hours, or None."""P = Query()cutoff = (datetime.now() - timedelta(hours=window_hours)).isoformat()recent = db.search((P.item_id == item_id) & (P.timestamp >= cutoff))prices = [r["price"]forrinrecent ifr.get("price")is not None]returnmin(prices)ifprices elseNonedef get_last_alert_time(db,item_id):"""Return the timestamp of the most recent alerted reading, or None."""P = Query()alerted = db.search((P.item_id == item_id) & (P.alerted == True)) # noqa:E712ifnot alerted:returnNonemost_recent = max(alerted,key=lambda r:r.get("timestamp",""))returndatetime.fromisoformat(most_recent["timestamp"])def decide(current,baseline,last_alert_at,now):"""Pure function. Returns (should_alert, reason_string)."""ifbaseline is None:returnFalse,"no recent baseline (re-establishing)"ifcurrent >= baseline:ifcurrent == baseline:returnFalse,f"matches 24h low ${baseline:.2f}"returnFalse,f"above 24h low ${baseline:.2f}"drop = baseline - currentpct = (drop / baseline) * 100ifdrop < MIN_DROP_DOLLARS or pct < MIN_DROP_PCT:returnFalse,(f"drop -${drop:.2f}/-{pct:.2f}% below threshold "f"(need >=${MIN_DROP_DOLLARS:.2f} AND >={MIN_DROP_PCT}%)")iflast_alert_at is not None:hours_since = (now - last_alert_at).total_seconds() / 3600if hours_since <COOLDOWN_HOURS:returnFalse,(f"cooldown active ({hours_since:.1f}h since last alert, "f"need {COOLDOWN_HOURS}h)")returnTrue,f"new 24h low (was ${baseline:.2f}, drop -${drop:.2f}/-{pct:.2f}%)"
# storage.pyfrom datetime importdatetime,timedeltafromloguru import logger
from tinydb importQueryMIN_DROP_PCT = 2.0MIN_DROP_DOLLARS = 1.00COOLDOWN_HOURS = 6BASELINE_WINDOW_HOURS = 24HISTORY_RETENTION_DAYS = 30def prune_old_entries(db,retention_days=HISTORY_RETENTION_DAYS):"""Delete readings older than retention_days so the file does not grow without limit."""P = Query()cutoff = (datetime.now() - timedelta(days=retention_days)).isoformat()removed = db.remove(P.timestamp < cutoff)if removed:logger.info(f"Pruned {len(removed)} entries older than {retention_days}d")def get_baseline_price(db,item_id,window_hours=BASELINE_WINDOW_HOURS):"""Return the lowest price seen for this item_id in the last window_hours, or None."""P = Query()cutoff = (datetime.now() - timedelta(hours=window_hours)).isoformat()recent = db.search((P.item_id == item_id) & (P.timestamp >= cutoff))prices = [r["price"]forrinrecent ifr.get("price")is not None]returnmin(prices)ifprices elseNonedef get_last_alert_time(db,item_id):"""Return the timestamp of the most recent alerted reading, or None."""P = Query()alerted = db.search((P.item_id == item_id) & (P.alerted == True)) # noqa:E712ifnot alerted:returnNonemost_recent = max(alerted,key=lambda r:r.get("timestamp",""))returndatetime.fromisoformat(most_recent["timestamp"])def decide(current,baseline,last_alert_at,now):"""Pure function. Returns (should_alert, reason_string)."""ifbaseline is None:returnFalse,"no recent baseline (re-establishing)"ifcurrent >= baseline:ifcurrent == baseline:returnFalse,f"matches 24h low ${baseline:.2f}"returnFalse,f"above 24h low ${baseline:.2f}"drop = baseline - currentpct = (drop / baseline) * 100ifdrop < MIN_DROP_DOLLARS or pct < MIN_DROP_PCT:returnFalse,(f"drop -${drop:.2f}/-{pct:.2f}% below threshold "f"(need >=${MIN_DROP_DOLLARS:.2f} AND >={MIN_DROP_PCT}%)")iflast_alert_at is not None:hours_since = (now - last_alert_at).total_seconds() / 3600if hours_since <COOLDOWN_HOURS:returnFalse,(f"cooldown active ({hours_since:.1f}h since last alert, "f"need {COOLDOWN_HOURS}h)")returnTrue,f"new 24h low (was ${baseline:.2f}, drop -${drop:.2f}/-{pct:.2f}%)"
# storage.pyfrom datetime importdatetime,timedeltafromloguru import logger
from tinydb importQueryMIN_DROP_PCT = 2.0MIN_DROP_DOLLARS = 1.00COOLDOWN_HOURS = 6BASELINE_WINDOW_HOURS = 24HISTORY_RETENTION_DAYS = 30def prune_old_entries(db,retention_days=HISTORY_RETENTION_DAYS):"""Delete readings older than retention_days so the file does not grow without limit."""P = Query()cutoff = (datetime.now() - timedelta(days=retention_days)).isoformat()removed = db.remove(P.timestamp < cutoff)if removed:logger.info(f"Pruned {len(removed)} entries older than {retention_days}d")def get_baseline_price(db,item_id,window_hours=BASELINE_WINDOW_HOURS):"""Return the lowest price seen for this item_id in the last window_hours, or None."""P = Query()cutoff = (datetime.now() - timedelta(hours=window_hours)).isoformat()recent = db.search((P.item_id == item_id) & (P.timestamp >= cutoff))prices = [r["price"]forrinrecent ifr.get("price")is not None]returnmin(prices)ifprices elseNonedef get_last_alert_time(db,item_id):"""Return the timestamp of the most recent alerted reading, or None."""P = Query()alerted = db.search((P.item_id == item_id) & (P.alerted == True)) # noqa:E712ifnot alerted:returnNonemost_recent = max(alerted,key=lambda r:r.get("timestamp",""))returndatetime.fromisoformat(most_recent["timestamp"])def decide(current,baseline,last_alert_at,now):"""Pure function. Returns (should_alert, reason_string)."""ifbaseline is None:returnFalse,"no recent baseline (re-establishing)"ifcurrent >= baseline:ifcurrent == baseline:returnFalse,f"matches 24h low ${baseline:.2f}"returnFalse,f"above 24h low ${baseline:.2f}"drop = baseline - currentpct = (drop / baseline) * 100ifdrop < MIN_DROP_DOLLARS or pct < MIN_DROP_PCT:returnFalse,(f"drop -${drop:.2f}/-{pct:.2f}% below threshold "f"(need >=${MIN_DROP_DOLLARS:.2f} AND >={MIN_DROP_PCT}%)")iflast_alert_at is not None:hours_since = (now - last_alert_at).total_seconds() / 3600if hours_since <COOLDOWN_HOURS:returnFalse,(f"cooldown active ({hours_since:.1f}h since last alert, "f"need {COOLDOWN_HOURS}h)")returnTrue,f"new 24h low (was ${baseline:.2f}, drop -${drop:.2f}/-{pct:.2f}%)"
MIN_DROP_PCT = 2.0 and MIN_DROP_DOLLARS = 1.00 are AND-gated. A drop must pass both. Tune these for your product range.
COOLDOWN_HOURS = 6 usually keeps the same product from triggering repeated alerts when the price moves up and down near the threshold. 6 hours is on the looser side. Once you have a week of alert history, consider tightening this to 24 hours.
BASELINE_WINDOW_HOURS = 24 sets the lookback window for a new low. A 24-hour window typically covers Walmart's day-to-day price changes.
HISTORY_RETENTION_DAYS = 30 caps how far back readings are kept. prune_old_entries() deletes anything older on each run, so price_history.json does not grow without limit.
Step 6: Slack alerts
Apprise hides most of the channel format, so the same send_alert call usually works for Slack, Discord, and other services.
# alerts.pyimportosimportapprisefromloguru importloggerfromscraper import PriceResult
from config importProductConfignotifier = apprise.Apprise()forurlinos.environ.get("APPRISE_URLS","").strip().splitlines():url = url.strip()if url:notifier.add(url)def _format_body(result: PriceResult,prior_price: float) -> str:assert result.priceis not Nonedrop = prior_price - result.pricepct = (drop / prior_price) * 100lines = [f"Previous: ${prior_price:.2f}",f"Current: ${result.price:.2f}",f"Drop: ${drop:.2f} (-{pct:.2f}%)",]
# Walmart's wasPrice / listPrice as a separate comparison anchor
msrp_anchor,msrp_label = None,Noneifresult.was_priceis not None and result.was_price > result.price:msrp_anchor,msrp_label = result.was_price,"vs Was"elif result.list_priceis not None and result.list_price > result.price:msrp_anchor,msrp_label = result.list_price,"vs MSRP"ifmsrp_anchor is not None:msrp_drop = msrp_anchor - result.pricemsrp_pct = (msrp_drop / msrp_anchor) * 100lines.append(f"{msrp_label}: ${msrp_anchor:.2f} (-${msrp_drop:.2f} / -{msrp_pct:.2f}%)")ifresult.unit_price_display:lines.append(f"Per unit: {result.unit_price_display}")ifresult.buybox_price_displayand result.seller_typeand result.seller_type != "INTERNAL":lines.append(f"Buybox: {result.buybox_price_display}")tags = []ifresult.offer_type:tags.append(result.offer_type.replace("Price","").upper())ifresult.is_price_event:tags.append("EVENT-PRICING")ifresult.seller_typeand result.seller_type != "INTERNAL":seller = result.seller_nameor "3rd-party"tags.append(f"SOLD BY {seller.upper()}")if tags:lines.append(f"Tags: {' | '.join(tags)}")ifresult.availabilityand result.availabilitynotin("Unknown","In stock"):lines.append(f"Stock: {result.availability}")lines.append("")lines.append(f"https://www.walmart.com/ip/{result.item_id}")return"\n".join(lines)def send_alert(result: PriceResult,product: ProductConfig,prior_price: float) -> bool:"""Returns True if delivery confirmed, False otherwise.
The caller uses the returnvalue to decide whether to mark the readingas
alerted inTinyDB. Onlymarking on success keeps the cooldown correctacross transient Slack outages.
"""
assert result.priceis not Nonetitle = f"Price Drop: {product.name}"body = _format_body(result,prior_price)iflen(notifier) == 0:logger.warning(f"No notification services configured! {title}")returnFalseifnotifier.notify(title=title,body=body):logger.success(f"Alert sent for {result.item_id}: ${result.price:.2f} (was ${prior_price:.2f})")returnTruelogger.error(f"Alert delivery failed for {result.item_id}: "f"${result.price:.2f} (was ${prior_price:.2f})")returnFalse
# alerts.pyimportosimportapprisefromloguru importloggerfromscraper import PriceResult
from config importProductConfignotifier = apprise.Apprise()forurlinos.environ.get("APPRISE_URLS","").strip().splitlines():url = url.strip()if url:notifier.add(url)def _format_body(result: PriceResult,prior_price: float) -> str:assert result.priceis not Nonedrop = prior_price - result.pricepct = (drop / prior_price) * 100lines = [f"Previous: ${prior_price:.2f}",f"Current: ${result.price:.2f}",f"Drop: ${drop:.2f} (-{pct:.2f}%)",]
# Walmart's wasPrice / listPrice as a separate comparison anchor
msrp_anchor,msrp_label = None,Noneifresult.was_priceis not None and result.was_price > result.price:msrp_anchor,msrp_label = result.was_price,"vs Was"elif result.list_priceis not None and result.list_price > result.price:msrp_anchor,msrp_label = result.list_price,"vs MSRP"ifmsrp_anchor is not None:msrp_drop = msrp_anchor - result.pricemsrp_pct = (msrp_drop / msrp_anchor) * 100lines.append(f"{msrp_label}: ${msrp_anchor:.2f} (-${msrp_drop:.2f} / -{msrp_pct:.2f}%)")ifresult.unit_price_display:lines.append(f"Per unit: {result.unit_price_display}")ifresult.buybox_price_displayand result.seller_typeand result.seller_type != "INTERNAL":lines.append(f"Buybox: {result.buybox_price_display}")tags = []ifresult.offer_type:tags.append(result.offer_type.replace("Price","").upper())ifresult.is_price_event:tags.append("EVENT-PRICING")ifresult.seller_typeand result.seller_type != "INTERNAL":seller = result.seller_nameor "3rd-party"tags.append(f"SOLD BY {seller.upper()}")if tags:lines.append(f"Tags: {' | '.join(tags)}")ifresult.availabilityand result.availabilitynotin("Unknown","In stock"):lines.append(f"Stock: {result.availability}")lines.append("")lines.append(f"https://www.walmart.com/ip/{result.item_id}")return"\n".join(lines)def send_alert(result: PriceResult,product: ProductConfig,prior_price: float) -> bool:"""Returns True if delivery confirmed, False otherwise.
The caller uses the returnvalue to decide whether to mark the readingas
alerted inTinyDB. Onlymarking on success keeps the cooldown correctacross transient Slack outages.
"""
assert result.priceis not Nonetitle = f"Price Drop: {product.name}"body = _format_body(result,prior_price)iflen(notifier) == 0:logger.warning(f"No notification services configured! {title}")returnFalseifnotifier.notify(title=title,body=body):logger.success(f"Alert sent for {result.item_id}: ${result.price:.2f} (was ${prior_price:.2f})")returnTruelogger.error(f"Alert delivery failed for {result.item_id}: "f"${result.price:.2f} (was ${prior_price:.2f})")returnFalse
# alerts.pyimportosimportapprisefromloguru importloggerfromscraper import PriceResult
from config importProductConfignotifier = apprise.Apprise()forurlinos.environ.get("APPRISE_URLS","").strip().splitlines():url = url.strip()if url:notifier.add(url)def _format_body(result: PriceResult,prior_price: float) -> str:assert result.priceis not Nonedrop = prior_price - result.pricepct = (drop / prior_price) * 100lines = [f"Previous: ${prior_price:.2f}",f"Current: ${result.price:.2f}",f"Drop: ${drop:.2f} (-{pct:.2f}%)",]
# Walmart's wasPrice / listPrice as a separate comparison anchor
msrp_anchor,msrp_label = None,Noneifresult.was_priceis not None and result.was_price > result.price:msrp_anchor,msrp_label = result.was_price,"vs Was"elif result.list_priceis not None and result.list_price > result.price:msrp_anchor,msrp_label = result.list_price,"vs MSRP"ifmsrp_anchor is not None:msrp_drop = msrp_anchor - result.pricemsrp_pct = (msrp_drop / msrp_anchor) * 100lines.append(f"{msrp_label}: ${msrp_anchor:.2f} (-${msrp_drop:.2f} / -{msrp_pct:.2f}%)")ifresult.unit_price_display:lines.append(f"Per unit: {result.unit_price_display}")ifresult.buybox_price_displayand result.seller_typeand result.seller_type != "INTERNAL":lines.append(f"Buybox: {result.buybox_price_display}")tags = []ifresult.offer_type:tags.append(result.offer_type.replace("Price","").upper())ifresult.is_price_event:tags.append("EVENT-PRICING")ifresult.seller_typeand result.seller_type != "INTERNAL":seller = result.seller_nameor "3rd-party"tags.append(f"SOLD BY {seller.upper()}")if tags:lines.append(f"Tags: {' | '.join(tags)}")ifresult.availabilityand result.availabilitynotin("Unknown","In stock"):lines.append(f"Stock: {result.availability}")lines.append("")lines.append(f"https://www.walmart.com/ip/{result.item_id}")return"\n".join(lines)def send_alert(result: PriceResult,product: ProductConfig,prior_price: float) -> bool:"""Returns True if delivery confirmed, False otherwise.
The caller uses the returnvalue to decide whether to mark the readingas
alerted inTinyDB. Onlymarking on success keeps the cooldown correctacross transient Slack outages.
"""
assert result.priceis not Nonetitle = f"Price Drop: {product.name}"body = _format_body(result,prior_price)iflen(notifier) == 0:logger.warning(f"No notification services configured! {title}")returnFalseifnotifier.notify(title=title,body=body):logger.success(f"Alert sent for {result.item_id}: ${result.price:.2f} (was ${prior_price:.2f})")returnTruelogger.error(f"Alert delivery failed for {result.item_id}: "f"${result.price:.2f} (was ${prior_price:.2f})")returnFalse
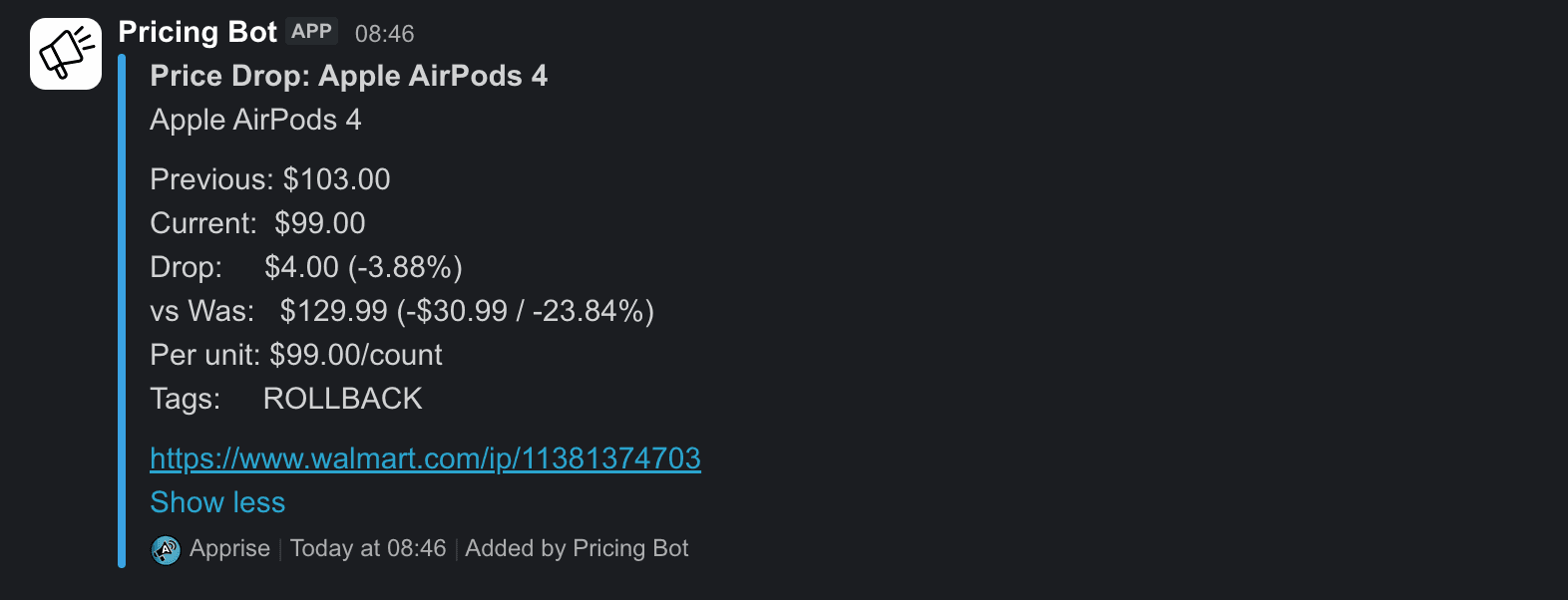
Here is what the Slack alert looks like:
Previous: is the 24-hour rolling baseline the scraper has stored. It is not Walmart's wasPrice or list price. vs Was: shows the wasPrice value as a separate row when the page has it. This way the reader sees the recent drop and also the bigger gap from Walmart's prior price.
Optional rows (vs Was, vs MSRP, Per unit, Buybox, Tags, Stock) typically appear when the page has them.
Name it (e.g. "Walmart Price Monitor") and pick the workspace.
In the left sidebar choose Incoming Webhooks and switch it on.
Click Add New Webhook to Workspace, pick the channel, and click Allow.
Copy the webhook URL. It looks like https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX.
Convert to Apprise format: the URL https://hooks.slack.com/services/A/B/C becomes slack://A/B/C. Set this as the APPRISE_URLS environment variable, one URL per line.
A message should appear in the channel within a few seconds.
Step 7: Main loop
check_once.py runs once per invocation. GitHub Actions or systemd calls it at a fixed interval.
# check_once.pyimportsys,jsonfromdatetime import datetime
from loguru importloggerfrompydantic import TypeAdapter
from tinydb importTinyDBfromscraper import WalmartPriceScraper
from config importProductConfigfromalerts import send_alert
from storage importprune_old_entries,get_baseline_price,get_last_alert_time,decidedef main():withopen("products.json")as f:data = json.load(f)products = TypeAdapter(list[ProductConfig]).validate_python(data["products"])logger.info(f"Checking {len(products)} products")db = TinyDB("price_history.json")prune_old_entries(db)scraper = WalmartPriceScraper()now = datetime.now()successes = failures = drops_alerted = 0forproductinproducts:result = scraper.get_price(product.item_id)ifnot(result andresult.priceis not None):logger.warning(f"Failed to get price for {product.name} ({product.item_id})")failures += 1continuebaseline = get_baseline_price(db,product.item_id)last_alert_at = get_last_alert_time(db,product.item_id)should_alert,reason = decide(result.price,baseline,last_alert_at,now)successes += 1delivered = Falseif should_alert:assert baseline is not Nonedelivered = send_alert(result,product,baseline)if delivered:drops_alerted += 1logger.info(f"{product.name}: ${result.price:.2f} | {reason}")
# Mark alerted only on confirmed delivery,so the cooldown does not
# lock out the next cycle when a Slack outage drops an alert.
record = result.model_dump(mode="json")record["alerted"] = delivereddb.insert(record)logger.info(f"Cycle done. {successes} ok, {failures} failed, {drops_alerted} alert(s)")ifsuccesses == 0and failures > 0:sys.exit(1)if__name__ == "__main__":main()
# check_once.pyimportsys,jsonfromdatetime import datetime
from loguru importloggerfrompydantic import TypeAdapter
from tinydb importTinyDBfromscraper import WalmartPriceScraper
from config importProductConfigfromalerts import send_alert
from storage importprune_old_entries,get_baseline_price,get_last_alert_time,decidedef main():withopen("products.json")as f:data = json.load(f)products = TypeAdapter(list[ProductConfig]).validate_python(data["products"])logger.info(f"Checking {len(products)} products")db = TinyDB("price_history.json")prune_old_entries(db)scraper = WalmartPriceScraper()now = datetime.now()successes = failures = drops_alerted = 0forproductinproducts:result = scraper.get_price(product.item_id)ifnot(result andresult.priceis not None):logger.warning(f"Failed to get price for {product.name} ({product.item_id})")failures += 1continuebaseline = get_baseline_price(db,product.item_id)last_alert_at = get_last_alert_time(db,product.item_id)should_alert,reason = decide(result.price,baseline,last_alert_at,now)successes += 1delivered = Falseif should_alert:assert baseline is not Nonedelivered = send_alert(result,product,baseline)if delivered:drops_alerted += 1logger.info(f"{product.name}: ${result.price:.2f} | {reason}")
# Mark alerted only on confirmed delivery,so the cooldown does not
# lock out the next cycle when a Slack outage drops an alert.
record = result.model_dump(mode="json")record["alerted"] = delivereddb.insert(record)logger.info(f"Cycle done. {successes} ok, {failures} failed, {drops_alerted} alert(s)")ifsuccesses == 0and failures > 0:sys.exit(1)if__name__ == "__main__":main()
# check_once.pyimportsys,jsonfromdatetime import datetime
from loguru importloggerfrompydantic import TypeAdapter
from tinydb importTinyDBfromscraper import WalmartPriceScraper
from config importProductConfigfromalerts import send_alert
from storage importprune_old_entries,get_baseline_price,get_last_alert_time,decidedef main():withopen("products.json")as f:data = json.load(f)products = TypeAdapter(list[ProductConfig]).validate_python(data["products"])logger.info(f"Checking {len(products)} products")db = TinyDB("price_history.json")prune_old_entries(db)scraper = WalmartPriceScraper()now = datetime.now()successes = failures = drops_alerted = 0forproductinproducts:result = scraper.get_price(product.item_id)ifnot(result andresult.priceis not None):logger.warning(f"Failed to get price for {product.name} ({product.item_id})")failures += 1continuebaseline = get_baseline_price(db,product.item_id)last_alert_at = get_last_alert_time(db,product.item_id)should_alert,reason = decide(result.price,baseline,last_alert_at,now)successes += 1delivered = Falseif should_alert:assert baseline is not Nonedelivered = send_alert(result,product,baseline)if delivered:drops_alerted += 1logger.info(f"{product.name}: ${result.price:.2f} | {reason}")
# Mark alerted only on confirmed delivery,so the cooldown does not
# lock out the next cycle when a Slack outage drops an alert.
record = result.model_dump(mode="json")record["alerted"] = delivereddb.insert(record)logger.info(f"Cycle done. {successes} ok, {failures} failed, {drops_alerted} alert(s)")ifsuccesses == 0and failures > 0:sys.exit(1)if__name__ == "__main__":main()
In normal operation the runner exits non-zero when every product in the cycle fails. GitHub Actions and systemd can send failure notifications based on this exit code.
The repo also ships run_locally.py, a thin wrapper around check_once.py that loops on an interval. It is useful for sanity-checking the stack on a laptop before deploying.
Deploy continuously
The script typically runs on a schedule. There are two main options. One is a $5/month Linux VPS with systemd, shown below. The other is the GitHub Actions cron workflow that runs the same script for free on GitHub's runners.
Option 1: systemd on a VPS. Copy the project files to /opt/walmart-monitor and create a Python virtual environment:
cd /opt/walmart-monitorpython3 -m venv .venv
.venv/bin/pip install -r requirements.txt
cd /opt/walmart-monitorpython3 -m venv .venv
.venv/bin/pip install -r requirements.txt
cd /opt/walmart-monitorpython3 -m venv .venv
.venv/bin/pip install -r requirements.txt
Save the proxies one per line in /opt/walmart-monitor/proxies.txt. Then create /etc/systemd/system/walmart-monitor.timer and walmart-monitor.service :
Replace slack://A/B/C with the Slack webhook URL in Apprise format from Step 6. The bash wrapper in ExecStart loads PROXIES from proxies.txt at run time, which is a clean way to keep multi-line proxy lists out of the unit file. Then run systemctl daemon-reload && systemctl enable --now walmart-monitor.timer. The timer fires every 30 minutes (*:0/30 means at :00 and :30 of each hour).
Option 2: GitHub Actions. The source repo includes .github/workflows/monitor.yml, which runs check_once.py on the same 30-minute schedule. To enable it on your fork:
Fork the repo. Make the fork private (the workflow commits price_history.json back, which records the products being monitored).
Add PROXIES and APPRISE_URLS as repository secrets (Settings → Secrets and variables → Actions).
Open the Actions tab and run the workflow once to confirm it works.
After that, the workflow runs roughly every 30 minutes on GitHub's runners (cron is best-effort and can be delayed under load).
For async deployments at scale, our VPS plans start at $30/month and run on the same network as the proxy pool.
Troubleshooting
Datacenter IPs are sometimes sold as residential.
Test
Real residential / consumer-ISP
Datacenter or fake
Fraud-score API
Low score
High score
Reverse DNS
ISP hostname (Comcast, Verizon, AT&T)
Hosting provider (AWS, OVH, DigitalOcean)
Geolocation consistency
Stays in one region
Jumps between regions
Run an IP through our proxy checker to get the fraud score, ASN, hostname, geolocation, VPN/Proxy/Tor detection, WebRTC/DNS leak detection, and live speed tests to Amazon, Google, and YouTube.
Are prices not parsing? If the __NEXT_DATA__ blob is present but the price is None, the item is probably out of stock or its priceInfo has no currentPrice value. The scraper returns None and saves the reading. It does not send an alert. This is intentional. If the blob itself is missing, Walmart has most likely changed the page structure. Check script#__NEXT_DATA__ in DevTools on a fresh page.
All requests return the "Robot or human?" challenge. If the table above flagged your IPs as datacenter, that is usually the cause. Switch to consumer-ISP IPs.
Are all proxies timing out? Check that the proxy account is active. Also check that your machine's IP is in the proxy IP allowlist. Then run https://www.walmart.com/robots.txt through one proxy with curl_cffi. A timeout there usually points to a routing issue on the provider's side. If that request works, the firewall on the host is most likely blocking outbound traffic on the proxy port.
No alerts arrive in Slack even when prices drop. Verify the Slack URL with the apprise -vv command from Step 6. Then check that the drop is above the thresholds in storage.py. A $0.10 drop on a $30 item is 0.3%. This is below the default 2% threshold. The scraper does not send the alert.
Is it still not working after these checks? For proxy-related issues, our Discord is the quickest channel in practice, staffed 24/7. For TLS bugs, check the curl_cffi issue tracker.
Scaling and adapting
Common next steps:
Scale the proxy pool. Switch the synchronous loop to curl_cffi.AsyncSession and asyncio.gather(). With roughly 50 ISP proxies running in parallel, this can handle a few thousand products at hourly cadence. As the catalog grows, add IPs in proportion. When one cycle takes close to the scheduling interval, also add a file lock around writes to price_history.json. On Linux you can use flock. TinyDB does not support concurrent writes, and overlapping cycles can corrupt the file.
Move to a larger plan. As the catalog grows past a few thousand, the proxy pool typically becomes the bottleneck. Business is 100 IPs at $125/month; Enterprise is 254 IPs (a full /24 subnet) at $300/month.
Run different cadences by priority. Run schedule.every(15).minutes.do(check_high_priority) for flash deals and schedule.every(6).hours.do(check_low_priority) for wishlist items. Both share the scraper and storage layer.
Adapt to walmart.ca or walmart.com.mx. The JSON path is usually the same. The URL host and currency parsing usually change.
Adapt the stack for JavaScript-gated pricing. Some items (for example pharmacy or service items) need JavaScript to load the price. For these, replace curl_cffi with a headless browser. The rest of the stack is mostly the same.
Adapt the database for larger catalogs. For 5,000 or more products at sub-hourly cadence, you typically want to replace TinyDB with something like PostgreSQL and a queue.
Reuse the playbook for Amazon. The TLS impersonation, ISP proxies, and decision layer usually transfer over with minor changes. The selectors and challenge markers typically change. See how to monitor Amazon product prices for the Amazon walkthrough.
Bottom line
Reliable Walmart price monitoring usually comes down to two things: matching a browser's TLS fingerprint, and using IPs with consumer-ISP reputation. Once a request gets through, the price fields tend to be in the __NEXT_DATA__ JSON blob, so parsing is straightforward. The alert thresholds in storage.py usually need tuning. Start with the 2% / $1 / 6h defaults and adjust based on which alerts you actually act on.
If you don't have an ISP proxy pool yet, our ISP proxies start at $65/month for 50 IPs with unlimited bandwidth. A $1 one-time verification also gives you platform access if you want to test first. That covers a few hundred products at hourly cadence sequentially, or a few thousand with the async upgrade in Scaling and adapting.